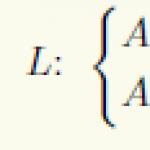DB Lecture Capítulo 2 BASES DE DATOS RELACIONALES 2.1. Términos y definiciones El desarrollo de las bases de datos relacionales se inició a finales de la década de 1960, cuando aparecieron los primeros trabajos, en los que se discutían las posibilidades de utilizar los métodos de representación de datos formalizados en forma de tablas que eran familiares para un especialista. Algunos expertos llamaron a esta forma de presentar la información como tablas de decisión, otros, algoritmos tabulares. Los teóricos de las bases de datos relacionales llamaron a la forma tabular de representar la información como modelos lógicos de datos. Se considera que el fundador de la teoría de las bases de datos relacionales es un empleado de IBM, el Dr. EF Codd, quien publicó el 6 de junio de 1970 el artículo "Un modelo relacional de datos para grandes bancos de datos compartidos" "Un modelo relacional de datos para Grandes bancos de datos compartidos ". En este artículo, por primera vez, se utilizó el término "modelo de datos relacionales", que sentó las bases para las bases de datos relacionales. La teoría de las bases de datos relacionales se desarrolló en la década de 1970. en los Estados Unidos por el Dr. E. F. Codd, se basó en el aparato matemático de la teoría de conjuntos. Demostró que cualquier conjunto de datos PUEDE representarse en forma de tablas bidimensionales de un tipo especial, conocidas en matemáticas como relaciones. De la palabra inglesa "relación" "relación") y vino el nombre "modelo de datos relacionales". En la actualidad, la base teórica para el diseño de bases de datos (DB) es el aparato matemático del álgebra relacional (ver Sección 1.2). Por lo tanto, una base de datos relacional es información (datos) sobre objetos, presentada en forma de matrices bidimensionales: tablas, unidas por ciertos enlaces. La base de datos también puede constar de una tabla. Antes de continuar con el estudio de las bases de datos relacionales, consideremos los términos y definiciones utilizados en la teoría y la práctica. Tabla de base de datos- matriz bidimensional que contiene información sobre una clase de objetos. En la teoría del álgebra relacional, una matriz bidimensional (tabla) se llama actitud. La tabla consta de los siguientes elementos: campo, celda, registro (Fig. 2.1). Campo contiene los valores de uno de los atributos que caracterizan a los objetos de la base de datos. El número de campos de la tabla corresponde al número de signos que caracterizan los objetos de la base de datos. 22 Celda contiene el valor específico del campo correspondiente (atributo de un objeto). Grabación- fila de la tabla. Contiene los valores de todos los signos que caracterizan a un objeto. El número de registros (líneas) corresponde al número de objetos, cuyos datos están contenidos en la tabla. En la teoría de bases de datos, el término grabación corresponde al concepto cor-tezh- una secuencia de atributos relacionados entre sí por la relación Y (Y). En teoría de grafos cortejo significa una rama simple de un árbol de gráficos dirigido. Mesa 2.1 muestra los términos utilizados en la teoría y la práctica del desarrollo de bases de datos relacionales. Uno de los conceptos importantes necesarios para construir una estructura óptima para las bases de datos relacionales es el concepto de clave o campo clave. Llave se considera un campo, cuyos valores determinan sin ambigüedades los valores de todos los demás campos de la tabla. Por ejemplo, el campo "Número de pasaporte", o "Número de identificación del contribuyente (TIN)", define de manera única las características de cualquier individuo (al compilar las tablas de la base de datos correspondiente PARA los departamentos de RR.HH. o el departamento de contabilidad de la empresa).  23
23
La clave de la tabla puede ser no uno, sino varios campos. En este caso, el conjunto de campos puede ser una clave posible para la tabla solo cuando se satisfacen dos condiciones independientes del tiempo: unicidad y minimidad. Cada campo que no forma parte de la clave principal se denomina campo sin clave en la tabla.
Unicidad clave significa que en un momento dado, la tabla de la base de datos no puede contener dos registros diferentes que tengan los mismos valores de campo clave. El cumplimiento de la condición de unicidad es obligatorio. Condición minimidad campos clave significa que solo la combinación de los valores de los campos seleccionados cumple los requisitos para la unicidad de los registros de la tabla de la base de datos. Esto también significa que ninguno de los campos incluidos en la clave se puede excluir sin violar la unicidad. Al formar la clave de una tabla de base de datos, que consta de varios campos, es necesario guiarse por las siguientes disposiciones: no debe incluir en la clave los campos de la tabla, cuyos valores identifican de manera única los registros en la tabla . Por ejemplo, no debe crear una clave que contenga simultáneamente los campos "número de pasaporte" y "número de identificación del contribuyente", ya que cada uno de estos atributos puede identificar de manera única los registros en la tabla; no puede incluir un campo no único en la clave, es decir, un campo cuyos valores se pueden repetir en la tabla. Cada tabla debe tener al menos una clave posible, que se elige como Clave primaria. Si hay campos en la tabla, los valores de cada uno de los cuales definen de forma única los registros, estos campos se pueden tomar como claves alternativas. Por ejemplo, si selecciona un número de identificación de contribuyente como clave principal, el número de pasaporte será una clave alternativa. 2.2. Normalización de tablas de bases de datos relacionales Una base de datos relacional es un conjunto de tablas que están relacionadas entre sí. El número de tablas en un archivo o una base de datos depende de muchos factores, los principales de los cuales son: la composición de los usuarios de la base de datos, asegurando la integridad de la información (especialmente importante en los sistemas de información multiusuario), asegurando la menor cantidad de memoria requerida y tiempo mínimo de procesamiento de datos. 24La consideración de estos factores en el diseño de bases de datos relacionales se lleva a cabo mediante los métodos de normalización de tablas y el establecimiento de conexiones entre ellas.
Normalizar tablas es una forma de dividir una tabla de base de datos en varias tablas que generalmente cumplen con los requisitos enumerados anteriormente. La normalización de una tabla es un cambio secuencial en la estructura de una tabla hasta que cumple con los requisitos de la última forma de normalización. Hay seis formas de normalización en total:- la primera forma normal (Primera forma normal - 1NF); la segunda forma normal (Segunda forma normal - 2NF); la tercera forma normal (Tercera forma normal - ЗNF); forma normal Boyes - Codd (Brice - Codd Forma normal -BCNF); cuarta forma normal (Foirth Forma normal - 4NF); quinta forma normal, o forma de proyección normal - conexiones (Quinta forma normal - 5NF, o PJ / NF ).
 26
26 
El campo "Dimensiones totales (largo x ancho x alto), mm", dividido en tres campos: "Largo, mm", "Ancho, mm", "Alto, mm". El campo clave de esta tabla puede ser el campo “Modelo de máquina” o “No. 2.3. Tomemos otro ejemplo. En la Fig. 2.2 muestra un fragmento de la hoja de puntuación de la prueba, que, como en el ejemplo anterior, no estaba originalmente destinada al procesamiento informático. Supongamos que queremos crear una base de datos para el procesamiento automatizado de los resultados de la sesión de prueba-examen de acuerdo con  27
27
con el contenido de la hoja de prueba y examen. Para hacer esto, transformamos el contenido del formulario en tablas de base de datos. Partiendo de la necesidad de cumplir con las condiciones de dependencia funcional entre los campos, es necesario conformar al menos dos tablas (Fig. 2.3) (los campos clave de cada tabla están en negrita). La primera tabla contiene los resultados de aprobar la prueba (examen) de cada alumno en una asignatura específica. La segunda tabla contiene los resultados finales de aprobar la prueba (examen) de un grupo específico de estudiantes en una materia específica. En la primera tabla, la clave es el campo "Nombre completo del estudiante", y en la segunda tabla, el campo "Disciplina". Las tablas deben estar vinculadas por los campos "Disciplina" Y "Código de grupo".
Las estructuras de tablas presentadas cumplen completamente con los requisitos de la primera forma normal, pero se caracterizan por los siguientes inconvenientes: agregar nuevos datos a las tablas requiere ingresar valores para todos los campos; en cada línea de cada tabla es necesario ingresar los valores repetidos de los campos "Disciplina", "Nombre completo del profesor", "Código del grupo". En consecuencia, con tal composición de tablas y su estructura, existe una clara redundancia de información, que, por supuesto, requerirá memoria adicional. Para evitar las desventajas enumeradas, es necesario llevar las tablas a la segunda o tercera forma normal. Segunda forma normal. Una tabla está en la segunda forma normal si cumple con los requisitos de la primera forma normal y todos sus campos que no están incluidos en la clave principal son completamente funcionales dependiendo de la clave principal. 28
Si una tabla tiene una clave primaria simple que consta de un solo campo, automáticamente se encuentra en la segunda forma normal.
Si la clave principal es compuesta, la tabla está opcionalmente en una segunda forma normal. Luego, debe dividirse en dos o más tablas de tal manera que la clave primaria identifique de manera única el valor en cualquier campo. Si la tabla tiene al menos un campo que no depende de la clave principal, se deben incluir columnas adicionales en la clave principal. Si no hay tales columnas, debe agregar una nueva columna. Con base en estas condiciones, que determinan la segunda forma normal, se pueden extraer las siguientes conclusiones sobre las características de las tablas compiladas (ver Fig. 2.3). En la primera tabla, no existe relación directa entre el campo clave y el campo "Nombre completo del profesor", ya que un pase o examen de la misma asignatura puede ser realizado por distintos profesores. En la tabla, hay una dependencia funcional completa solo entre todos los demás campos y el campo clave "Disciplina". Del mismo modo, en la segunda tabla, no existe una relación directa entre el campo clave y el campo "Nombre completo del profesor". Para optimizar la base de datos, en particular para reducir la cantidad de memoria requerida debido a la necesidad de repetir los valores de los campos "Disciplina" y "Nombre del profesor" en cada registro, es necesario cambiar la estructura de la base de datos - para transformar las tablas originales en la segunda forma normal. La composición de las tablas de la estructura de la base de datos modificada se muestra en la Fig. 2.4. La estructura de la base de datos convertida consta de seis tablas, dos de las cuales están interconectadas (los campos clave de cada tabla están en negrita). Todas las tablas satisfacen los requisitos de la segunda forma normal. Las tablas quinta y sexta tienen valores duplicados en los campos, pero dado que estos valores son números enteros en lugar de datos de texto, la cantidad total de memoria requerida para almacenar información es mucho menor que en las tablas originales (ver Fig. 2.1 ). Además, la nueva estructura de la base de datos brindará la capacidad de llenar las tablas por varios especialistas (divisiones de servicios de gestión). La optimización adicional de las tablas de la base de datos se reduce a llevarlas a la tercera forma normal. Tercera forma normal. Una tabla está en la tercera forma normal si satisface la definición de la segunda forma normal y ninguno de sus campos no clave depende funcionalmente de ningún otro campo no clave. 29

También puede decir que una tabla está en la tercera forma normal si está en la segunda forma normal y cada campo que no es de clave no depende transitivamente de la clave principal. El tercer requisito de formulario normal es que todos los campos que no son de clave solo dependen de la clave principal y no dependen unos de otros. De acuerdo con estos requisitos, como parte de las tablas de la base de datos (ver Fig. 2.3), la primera, segunda, tercera y cuarta tablas pertenecen a la tercera forma normal. Para llevar las tablas quinta y sexta a la tercera forma normal, crearemos una nueva tabla que contenga información sobre la composición de las materias para las que se realizan exámenes o pruebas en grupos de estudiantes. Como clave, crearemos un campo “Contador”, que establece el número de un registro en la tabla, ya que cada registro debe ser único. treinta
Como resultado, obtenemos una nueva estructura de base de datos, que se muestra en la Fig. 2.5 (los campos clave de cada tabla están en negrita). Esta estructura contiene siete tablas que cumplen con los requisitos del tercer formulario normal.
La forma normal de Boyce es Codd. Una tabla tiene la forma normal de Boyce-Codd solo si cualquier dependencia funcional entre sus campos se reduce a una dependencia funcional completa de una posible clave. De acuerdo con esta definición, en la estructura de la base de datos (ver Fig. 2.4), todas las tablas cumplen los requisitos de la forma normal de Boyes - Codd. La optimización adicional de las tablas de la base de datos debería reducirse a una descomposición completa de las tablas. Descomposición de la tabla completa se llama tal colección de un número arbitrario de sus proyecciones, cuya conexión coincide completamente con el contenido de la tabla. Una proyección es una copia de una tabla que no incluye una o más columnas de la nueva tabla. Cuarta forma normal. La cuarta forma normal es un caso especial de la quinta forma normal, cuando una descomposición completa debe ser una unión de dos proyecciones. 31
31 Es muy difícil encontrar una tabla que esté en cuarta forma normal, pero que no satisfaga la definición de quinta forma normal.
Quinta forma normal. Una tabla está en la quinta forma normal si y solo si todas las proyecciones contienen una clave posible en cada una de sus posiciones decorativas completas. Una tabla que no tiene una descomposición completa también se encuentra en la quinta forma normal. En la práctica, la optimización de las tablas de la base de datos termina en la tercera forma normal. La reducción de las tablas a la cuarta y quinta forma normal es, en nuestra opinión, de interés puramente teórico. En la práctica, este problema se resuelve mediante el desarrollo de consultas para crear una nueva tabla. 2.3. Diseñar relaciones entre tablas El proceso de normalización de las tablas iniciales de la base de datos le permite crear la estructura óptima del sistema de información: desarrollar una base de datos que requiera la menor cantidad de recursos de memoria y, como resultado, proporcione el menor tiempo de acceso a la información. Al mismo tiempo, dividir una tabla fuente en varias requiere el cumplimiento de una de las condiciones más importantes para el diseño de sistemas de información: garantizar la integridad de la información durante el funcionamiento de la base de datos. En el ejemplo anterior de normalización de las tablas originales (ver Fig. 2.3), de las dos tablas, finalmente obtuvimos siete tablas reducidas a la tercera y cuarta forma normal. Como muestra la práctica, en la producción y los negocios reales, las bases de datos son sistemas multiusuario. Esto se aplica tanto a la creación y mantenimiento de datos en tablas separadas como al uso de información para tomar decisiones. En el ejemplo considerado anteriormente, en un sistema de gestión de procesos educativos realmente funcional en una universidad o colegio, la formación inicial de los grupos de estudio la realizan los comités de admisión al inscribir a los postulantes en base a los resultados de los exámenes de ingreso. El mantenimiento adicional de la información sobre la composición de los estudiantes en grupos en las universidades se asigna a las oficinas del decano y en las universidades, a los departamentos educativos o estructuras relevantes. La composición de las disciplinas académicas en grupos está determinada por otros servicios o especialistas. La información sobre el profesorado se forma en los departamentos de personal. Los resultados de las pruebas y las sesiones de examen son necesarios para los jefes de la oficina y los departamentos del decano, incluso para tomar decisiones sobre la concesión de becas a 32 estudiantes exitosos o el "retiro de la beca" de los estudiantes reprobados. Cualquier cambio en cualquiera de las tablas de la base de datos debe encontrar un cambio adecuado en todas las demás tablas. Ésta es la esencia para garantizar la integridad de la base de datos. En la práctica, esta tarea se lleva a cabo mediante el establecimiento de vínculos entre las tablas de la base de datos. Formulemos las reglas básicas para establecer relaciones entre tablas. 1. Seleccione un maestro y un esclavo de las dos tablas vinculadas. 2. En cada tabla, seleccione un campo clave. El campo clave de la tabla principal se llama la clave principal. El campo clave de la tabla esclava se llama clave externa. 3. Los campos de la tabla delimitada deben ser del mismo tipo de datos. 4. Se establecen los siguientes tipos de enlaces entre tablas: "uno a uno"; Uno a muchos; Muchos a muchos: se establece una relación uno a uno cuando una fila particular de la tabla maestra está vinculada a una sola fila de la tabla subordinada en un momento dado; Se establece una relación de uno a muchos en los casos en que una fila específica de la tabla principal en un momento dado 33 está asociado con múltiples filas de la tabla subordinada; en este caso, cualquier fila de la tabla subordinada está asociada con una sola fila de la tabla principal; Se establece una relación de muchos a muchos en los casos en que una fila particular de la tabla principal en cualquier momento está asociada con varias filas de la tabla subordinada y, al mismo tiempo, una fila de la tabla subordinada está asociada con varias filas de la tabla principal. mesa. Al cambiar el valor de la clave primaria en la tabla maestra, son posibles los siguientes comportamientos de la tabla dependiente. Cascada. Cuando cambian los datos de la clave principal en la tabla principal, cambian los datos de la clave externa correspondiente en la tabla dependiente. Todas las conexiones existentes se mantienen. Restringir. Si intenta cambiar el valor de la clave principal asociada con las filas de la tabla dependiente, los cambios se descartan. Se permite cambiar solo aquellos valores de la clave primaria para los cuales no se ha establecido ninguna conexión con la tabla dependiente. Establecimiento (Relación). Cuando los datos de la clave principal cambian, la clave externa se establece en un valor nulo (NULL). Se pierde la información de propiedad de la fila de la tabla dependiente. Si cambia varios valores de la clave principal, se forman varios grupos de filas en la tabla dependiente, que anteriormente estaban asociados con las claves modificadas. Después de eso, es imposible determinar qué fila se asoció con qué clave principal. En la Fig. 2.6 muestra los diagramas de conexiones entre las tablas de la base de datos mostradas en la Fig. 2.5. Preguntas de control 1. Dé definiciones a los siguientes elementos de la tabla de la base de datos: campo, celda, registro. 2. ¿Qué significan los conceptos "clave", "campo clave"? 3. ¿Qué campo de clave se llama clave principal y cuál se llama clave externa? 4. ¿Cuál es el proceso de normalización de las tablas de la base de datos? 5. ¿Qué cinco formas normales de tablas de bases de datos conoce? 6. Defina los siguientes tipos de relaciones entre las tablas de la base de datos: "uno a uno"; Uno a muchos; Muchos a muchos.
33 está asociado con múltiples filas de la tabla subordinada; en este caso, cualquier fila de la tabla subordinada está asociada con una sola fila de la tabla principal; Se establece una relación de muchos a muchos en los casos en que una fila particular de la tabla principal en cualquier momento está asociada con varias filas de la tabla subordinada y, al mismo tiempo, una fila de la tabla subordinada está asociada con varias filas de la tabla principal. mesa. Al cambiar el valor de la clave primaria en la tabla maestra, son posibles los siguientes comportamientos de la tabla dependiente. Cascada. Cuando cambian los datos de la clave principal en la tabla principal, cambian los datos de la clave externa correspondiente en la tabla dependiente. Todas las conexiones existentes se mantienen. Restringir. Si intenta cambiar el valor de la clave principal asociada con las filas de la tabla dependiente, los cambios se descartan. Se permite cambiar solo aquellos valores de la clave primaria para los cuales no se ha establecido ninguna conexión con la tabla dependiente. Establecimiento (Relación). Cuando los datos de la clave principal cambian, la clave externa se establece en un valor nulo (NULL). Se pierde la información de propiedad de la fila de la tabla dependiente. Si cambia varios valores de la clave principal, se forman varios grupos de filas en la tabla dependiente, que anteriormente estaban asociados con las claves modificadas. Después de eso, es imposible determinar qué fila se asoció con qué clave principal. En la Fig. 2.6 muestra los diagramas de conexiones entre las tablas de la base de datos mostradas en la Fig. 2.5. Preguntas de control 1. Dé definiciones a los siguientes elementos de la tabla de la base de datos: campo, celda, registro. 2. ¿Qué significan los conceptos "clave", "campo clave"? 3. ¿Qué campo de clave se llama clave principal y cuál se llama clave externa? 4. ¿Cuál es el proceso de normalización de las tablas de la base de datos? 5. ¿Qué cinco formas normales de tablas de bases de datos conoce? 6. Defina los siguientes tipos de relaciones entre las tablas de la base de datos: "uno a uno"; Uno a muchos; Muchos a muchos. Los conceptos básicos de las bases de datos relacionales son tipo de datos, dominio, atributo, tupla, clave primaria y relación. Demostremos el significado de estos conceptos utilizando el ejemplo de la relación EMPLEADOS, que contiene información sobre los empleados de una determinada organización:
1. Tipo de datos
Concepto tipo de datos en el modelo de datos relacionales es totalmente adecuado al concepto de tipo de datos en los lenguajes de programación. Normalmente, las bases de datos relacionales modernas permiten almacenar caracteres, datos numéricos, cadenas de bits, datos numéricos especializados (como "dinero"), así como datos "temporales" especiales (fecha, hora, intervalo de tiempo). Se está desarrollando activamente un enfoque para expandir las capacidades de los sistemas relacionales con tipos de datos abstractos (por ejemplo, los sistemas de la familia Ingres / Postgres tienen tales capacidades). En nuestro ejemplo, estamos tratando con tres tipos de datos: cadenas de caracteres, números enteros y dinero.
2. Dominio
Concepto dominio más específico para bases de datos, aunque tiene algunas analogías con subtipos en algunos lenguajes de programación. En su forma más general, un dominio se define especificando algún tipo de datos básico al que pertenecen los elementos del dominio, y una expresión lógica arbitraria aplicada al elemento del tipo de datos. Si esta expresión booleana se evalúa como verdadera, entonces el elemento de datos es un elemento de dominio. La interpretación intuitiva más correcta de la noción de dominio es la comprensión de un dominio como un conjunto potencial admisible de valores de un tipo dado. Por ejemplo, los "Nombres" de dominio en nuestro ejemplo se definen en el tipo base de cadenas de caracteres, pero sus valores pueden incluir solo aquellas cadenas que pueden representar un nombre (en particular, dichas cadenas no pueden comenzar con un signo suave). También debe tenerse en cuenta la carga semántica del concepto de dominio: los datos se consideran comparables solo si pertenecen al mismo dominio. En nuestro ejemplo, los valores de los dominios "Gap Numbers" y "Group Numbers" son de tipo entero, pero no son comparables. Tenga en cuenta que la mayoría de los DBMS relacionales no utilizan el concepto de dominio, aunque Oracle V.7 ya lo admite.
3. Esquema de relación, esquema de base de datos
Un esquema de relación es un conjunto de pares con nombre (nombre de atributo, nombre de dominio (o tipo si no se admite la noción de dominio)). El grado o "aridad" del esquema de relación es la cardinalidad de este conjunto. El grado de la relación EMPLEADOS es cuatro, es decir, es 4 ario. Si todos los atributos de una relación se definen en dominios diferentes, tiene sentido utilizar los nombres de los dominios correspondientes para nombrar los atributos (recordando, por supuesto, que este es solo un método de denominación conveniente y no elimina la distinción entre los conceptos de dominio y atributo). Un esquema de base de datos (en un sentido estructural) es un conjunto de esquemas de relación con nombre.
4. Tupla, relación
Una tupla correspondiente a un esquema de relación dado es un conjunto de pares (nombre de atributo, valor) que contiene una aparición de cada nombre de atributo que pertenece al esquema de relación. "Valor" es un valor de dominio válido para el atributo dado (o tipo de datos si no se admite la noción de dominio). Por lo tanto, el grado o "aridad" de la tupla, es decir el número de elementos en él coincide con la "aridad" del esquema de relación correspondiente. En términos simples, una tupla es una colección de valores con nombre de un tipo determinado.
Una relación es un conjunto de tuplas que corresponden al mismo esquema de relación. A veces, para evitar confusiones, dicen "relación de esquema" y "relación de instancia", a veces el esquema de una relación se denomina título de la relación, y la relación, como conjunto de tuplas, se denomina cuerpo de la relación. De hecho, el concepto de esquema de relación se acerca más al concepto de tipo de datos estructurados en los lenguajes de programación. Sería bastante lógico permitir definir por separado un esquema de relación y luego una o más relaciones con ese esquema.
La representación cotidiana habitual de una relación es una tabla, cuyo título es el diagrama de la relación y las filas son tuplas de la relación de instancia; en este caso, los nombres de los atributos nombran las columnas de esa tabla. Por lo tanto, a veces dicen "columna de tabla", que significa "atributo de relación". Una base de datos relacional es un conjunto de relaciones cuyos nombres son los mismos que los nombres de los esquemas de relaciones en el esquema de la base de datos.
Propiedades fundamentales de las relaciones
1.No hay tuplas duplicadas
La propiedad de que una relación no contiene tuplas duplicadas se deriva de la definición de una relación como un conjunto de tuplas. En la teoría de conjuntos clásica, por definición, cada conjunto consta de diferentes elementos. Esta propiedad implica que cada relación tiene una llamada clave primaria, un conjunto de atributos, cuyos valores determinan de forma única la tupla de la relación. Para cada relación, al menos el conjunto completo de sus atributos tiene esta propiedad. Sin embargo, en la definición formal de la clave primaria, es necesario asegurarse de que sea "mínima"; el conjunto de atributos de la clave primaria no debe incluir atributos que puedan descartarse sin perjuicio de la propiedad principal, para identificar sin ambigüedades una tupla. Concepto Clave primaria es extremadamente importante en relación con el concepto de integridad de la base de datos.
2.Falta de ordenación de tuplas.
La propiedad de que las tuplas de una relación no están ordenadas también es una consecuencia de definir una relación de instancia como un conjunto de tuplas. La ausencia del requisito de mantener el orden en el conjunto de tuplas de una relación le da al DBMS flexibilidad adicional al almacenar bases de datos en memoria externa y al ejecutar consultas a la base de datos. Esto no contradice el hecho de que al formular una consulta a la base de datos, por ejemplo, en el lenguaje SQL, puede requerir ordenar la tabla resultante de acuerdo con los valores de algunas columnas. Dicho resultado, en términos generales, no es una relación, sino una lista ordenada de tuplas.
3.Falta de ordenación de atributos.
Los atributos de relación no están ordenados porque, por definición, un esquema de relación tiene muchos pares (nombre de atributo, nombre de dominio). El nombre de atributo siempre se usa para referirse al valor de un atributo en una tupla de una relación. Esta propiedad teóricamente permite, por ejemplo, modificar los esquemas de relaciones existentes no solo agregando nuevos atributos, sino también eliminando atributos existentes. Sin embargo, en la mayoría de los sistemas existentes tal posibilidad no está permitida, y aunque el orden del conjunto de atributos de una relación no se requiere explícitamente, a menudo su orden en la forma lineal de definir el esquema de relación se usa como el orden implícito de la relación. atributos.
4.Atomicidad de los valores de los atributos.
Todos los valores de los atributos son atómicos. Esto se sigue de la definición de un dominio como un conjunto potencial de valores de un tipo de datos simple, es decir los valores de dominio no pueden contener conjuntos de valores (relaciones). Se suele decir que en las bases de datos relacionales solo se permiten relaciones normalizadas o relaciones representadas en la primera forma normal.
Modelo de datos relacionales. Según Date, el modelo relacional consta de tres partes que describen diferentes aspectos del enfoque relacional: la parte estructural, la parte de manipulación y la parte integral. En la parte estructural del modelo, se fija que la única estructura de datos utilizada en las bases de datos relacionales es una relación n-aria normalizada. La parte de manipulación del modelo afirma dos mecanismos fundamentales para manipular bases de datos relacionales: álgebra relacional y cálculo relacional. El primer mecanismo se basa principalmente en la teoría de conjuntos clásica (con algunos refinamientos), y el segundo, en el aparato lógico clásico del cálculo de predicados de primer orden.
La integridad de la entidad y los enlaces. Finalmente, en la parte integral del modelo de datos relacionales, se fijan dos requisitos básicos de integridad que deben ser soportados en cualquier DBMS relacional. El primer requisito se llama requisito de integridad de la entidad... Un objeto o entidad del mundo real en bases de datos relacionales corresponde a tuplas de relaciones. Específicamente, el requisito es que cualquier tupla de cualquier relación sea distinguible de cualquier otra tupla de esta relación, es decir, en otras palabras, cualquier relación debe tener una clave primaria. Como vimos en la sección anterior, este requisito se satisface automáticamente si las propiedades básicas de la relación no se violan en el sistema. El segundo requisito se llama Requisito de integridad por referencia y es algo más complejo. Obviamente, si las relaciones están normalizadas, las entidades complejas del mundo real se representan en una base de datos relacional en forma de varias tuplas de varias relaciones.
Operaciones relacionales y numeración.
Después de haber propuesto un modelo de datos relacionales, E.F. Codd también creó una herramienta para trabajar cómodamente con las relaciones: el álgebra relacional. Cada operación de esta álgebra usa una o más tablas (relaciones) como sus operandos y como resultado produce una nueva tabla, es decir le permite "cortar" o "pegar" tablas (Fig. 3.3).  Arroz. 3.3. Algunas operaciones del álgebra relacional
Arroz. 3.3. Algunas operaciones del álgebra relacional
Se han creado lenguajes de manipulación de datos que permiten implementar todas las operaciones del álgebra relacional y casi cualquier combinación de ellas. Entre ellos, los más comunes son SQL (Structured Query Language) y QBE (Quere-By-Example) [,]. Ambos son lenguajes de muy alto nivel, con la ayuda de los cuales el usuario especifica qué datos deben obtenerse sin precisar el procedimiento para obtenerlos. Con una sola consulta en cualquiera de estos idiomas, puede unir varias tablas en una tabla temporal y recortar las filas y columnas necesarias (selección y proyección).
Soporte de idioma de base de datos
Para trabajar con la base de datos, se utilizan lenguajes especiales, generalmente denominados lenguajes de base de datos.
En las primeras bases de datos, había 2 idiomas:
1. El lenguaje de definición para el esquema de la base de datos SDL.
2. Lenguaje de manipulación de datos DML.
El primero de ellos sirvió para definir la estructura lógica de la base de datos, y el segundo contenía un conjunto de operadores que permitían manipular los datos, es decir, ingresar a la base de datos y borrarlos. En los DBMS modernos, generalmente se admite un idioma que contiene todas las herramientas necesarias para trabajar con la base de datos. Este lenguaje permite tanto crear una base de datos como proporcionar una base de datos al usuario.
Con mucho, el idioma más común es
S estructurado
L idioma
Este lenguaje soporta y crea el esquema de la base de datos y permite manipular estos datos. Contiene todas las herramientas que necesita para garantizar la integridad de su base de datos. Estas restricciones de integridad están contenidas en directorios especiales que le permiten controlar la integridad de la base de datos a nivel de idioma. Los operadores especiales del lenguaje SQL definen las llamadas vistas de la base de datos. Ver: ϶ᴛᴏ consultas que se almacenan en la base de datos. Para el usuario, una vista es una tabla ϶ᴛᴏ con la ayuda de la cual puede restringir o expandir la visibilidad de la base de datos para un usuario de datos específico. El lenguaje SQL contiene operandos tan especiales que otorgan autorización de acceso a los objetos de la base de datos. Dado que diferentes usuarios tienen diferentes permisos para trabajar con datos, estos permisos se describen en tablas especiales, catálogos que se admiten en el nivel de idioma.
Los conceptos básicos de las bases de datos relacionales son: tipo de datos, dominio, atributo, tupla, clave primaria, relación.
El tipo de datos en el modelo relacional generalmente se entiende como el mismo tipo de datos en los lenguajes de programación, es decir, los datos pueden ser caracteres, numéricos, cadenas de bits, datos numéricos especiales (dinero), así como datos temporales especiales (tiempo, fecha, intervalo de tiempo).
En su forma más general, un dominio se determina especificando un cierto tipo de datos básicos al que pertenecen los elementos de este dominio, el concepto de dominio es su comprensión como un valor plural admisible de una base de datos. El dominio tiene una carga semántica. Los datos solo se consideran comparables si pertenecen al mismo dominio.
Es habitual entender una tupla como un conjunto de pares de elementos de base de datos que contienen una aparición de cada atributo semilla en el esquema de relación.
Esquema de relación: ϶ᴛᴏ conjunto de pares de elementos con nombre. Y en
tupla = nombre de atributo͵ valor, es decir, una tupla es una colección de valores con nombre de un tipo dado.
Relación - ϶ᴛᴏ un conjunto de tuplas correspondientes a algún esquema, es decir, una base de datos relacional - ϶ᴛᴏ un conjunto de relaciones cuyos nombres coinciden con los nombres de los esquemas de relaciones en la estructura de la base de datos.
Las bases de datos relacionales son las más extendidas en la actualidad, aunque, junto con las ventajas generalmente reconocidas, también tienen una serie de desventajas. Las ventajas del enfoque relacional incluyen:
La presencia de un pequeño conjunto de abstracciones que hacen relativamente fácil modelar la mayoría de las áreas temáticas comunes y permiten definiciones formales precisas, sin dejar de ser intuitivo;
La presencia de un aparato matemático simple y al mismo tiempo poderoso, basado principalmente en la teoría de conjuntos y la lógica matemática y que proporciona una base teórica para un enfoque relacional de la organización de bases de datos;
Posibilidad de manipulación de datos no navegables sin necesidad de conocer la organización física específica de las bases de datos en memoria externa.
Los sistemas relacionales tardaron mucho en generalizarse. Si bien los principales resultados teóricos en esta área se obtuvieron allá por los años 70, y al mismo tiempo aparecieron los primeros prototipos de DBMS relacionales, durante mucho tiempo se consideró imposible lograr una implementación efectiva de dichos sistemas. Sin embargo, las ventajas señaladas anteriormente y la acumulación gradual de métodos y algoritmos para organizar y administrar bases de datos relacionales llevaron al hecho de que a mediados de los 80, los sistemas relacionales prácticamente expulsaron a los primeros DBMS del mercado mundial.
Actualmente, el principal tema de crítica de los DBMS relacionales no es su falta de eficiencia, sino algunas limitaciones inherentes a estos sistemas (consecuencia directa de la simplicidad) cuando se utilizan en las denominadas áreas no tradicionales (los ejemplos más comunes son la automatización del diseño). sistemas), que requieren estructuras de datos extremadamente complejas. Otra desventaja de las bases de datos relacionales que se observa a menudo es la incapacidad de reflejar adecuadamente la semántica del dominio. En otras palabras, las posibilidades de representar el conocimiento sobre las especificidades semánticas del dominio en los sistemas relacionales son muy limitadas. La investigación moderna en el campo de los sistemas de posrelación se dedica principalmente a eliminar con precisión estas deficiencias.
Los conceptos básicos de las bases de datos relacionales son tipo de datos, dominio, atributo, tupla, clave principal y relación.
Concepto tipo de datos en el modelo de datos relacionales es totalmente adecuado al concepto de tipo de datos en los lenguajes de programación. Normalmente, las bases de datos relacionales modernas permiten almacenar caracteres, datos numéricos, cadenas de bits, datos numéricos especializados (como "dinero"), así como datos "temporales" especiales (fecha, hora, intervalo de tiempo). Se está desarrollando activamente un enfoque para expandir las capacidades de los sistemas relacionales con tipos de datos abstractos (por ejemplo, los sistemas de la familia Ingres / Postgres tienen tales capacidades).
Estructuras de datos del modelo relacional. El modelo de datos relacionales organiza y presenta datos en forma de tablas o relaciones. Relacional Es un término que proviene de las matemáticas y denota una tabla bidimensional simple. El enfoque relacional para construir bases de datos utiliza la terminología de la teoría de relaciones. La tabla bidimensional más simple se define como actitud.
mesa es el tipo de estructura de datos principal (objeto) del modelo relacional. La estructura de la tabla está determinada por la población columnas. Cada fila de la tabla contiene un valor en el correspondiente columna. No puede haber dos filas idénticas en una tabla. El número total de líneas no está limitado.
Columna coincide con algún elemento de datos - atributo, que es la estructura de datos más simple. No se pueden definir varios elementos, un grupo o un grupo repetido en una tabla como en la red y los modelos jerárquicos discutidos anteriormente. Cada columna de la tabla debe tener nombre el elemento de datos correspondiente (atributo).
La columna de la tabla con los valores del atributo correspondiente se llama dominio, y cadenas con valores de diferentes atributos - una tupla.
Relación de tabla relacional. En la Fig. 9 es una ilustración de una relación de tabla relacional R... Definicion formal relación R (tabla relacional) se basa en la idea de su dominios D I, (columnas) y tuplas K j (líneas). La relación R definida en los conjuntos de dominios (D i) es el subconjunto Producto cartesiano (directo) de dominios D 1 * D 2 *… .. * D n
Relación de mesa(ver Fig. 1) contiene columnas con los nombres de los elementos de datos - atributos (A 1, A 2, ...). Los valores de los atributos d están en la parte de contenido de la tabla y forman filas y columnas. Muchos valores de atributo en una columna forman uno dominio D i... Muchos valores de atributo en una línea forman uno cortejo Para j. Actitud R está formado por un conjunto de tuplas.
R = (Кj), J = 1- m Кj = (d 1j, d 2 j,… d nj),
donde n es el número de dominios de la relación; define dimensión de la relación;
j es el número de la tupla;
m es el número total de tuplas en la relación llamada co-número relación.
Figura 9. Ilustración de relación de tabla relacional
Dominio. En su forma más general, un dominio se define especificando algún tipo de datos básico al que pertenecen los elementos del dominio, y una expresión lógica arbitraria aplicada al elemento del tipo de datos. Si esta expresión booleana se evalúa como verdadera, entonces el elemento de datos es un elemento de dominio.
La interpretación intuitiva más correcta de la noción de dominio es la comprensión de un dominio como un conjunto potencial admisible de valores de un tipo dado. Por ejemplo, los "Nombres" de dominio en nuestro ejemplo se definen en el tipo base de cadenas de caracteres, pero sus valores pueden incluir solo aquellas cadenas que pueden representar un nombre (en particular, dichas cadenas no pueden comenzar con un signo suave).
También debe tenerse en cuenta la carga semántica del concepto de dominio: los datos se consideran comparables solo si pertenecen al mismo dominio. En nuestro ejemplo, los valores de los dominios "Gap Numbers" y "Group Numbers" son de tipo entero, pero no son comparables. Tenga en cuenta que la mayoría de los DBMS relacionales no utilizan el concepto de dominio, aunque Google V.7 ya lo admite.
Esquema de relación, esquema de base de datos. Un esquema de relación es un conjunto de pares con nombre (nombre de atributo, nombre de dominio (o tipo si no se admite la noción de dominio)). El grado o "aridad" del esquema de relación es la cardinalidad de este conjunto. El grado de la razón EJEMPLO es SEIS, es decir, es 6 ario. Si todos los atributos de una relación se definen en dominios diferentes, tiene sentido utilizar los nombres de los dominios correspondientes para nombrar los atributos (recordando, por supuesto, que este es solo un método de denominación conveniente y no elimina la distinción entre los conceptos de dominio y atributo). Un esquema de base de datos (en un sentido estructural) es un conjunto de esquemas de relación con nombre.
La lista, que da los nombres de las tablas relacionales, enumerando sus atributos (claves subrayadas) y las definiciones de claves externas se llama esquema de base de datos relacional. Es un resumen preliminar de la creación de la etapa del ciclo de vida de una base de datos relacional. Ejemplo:
TRABAJADOR [ ID DE TRABAJADOR, NOMBRE, TASA POR HORA, TIPO DE HABILIDAD, ID-SVPV]
Claves externas: TIPO DE HABILIDAD referenciado por HABILIDAD
TRABAJADOR referenciado SVPV-ID
ASIGNACIÓN [ ID DE TRABAJADOR, BLDG-ID, FECHA DE INICIO, NÚMERO DE DÍAS]
Claves externas: WORKER-ID al que se hace referencia en WORKER
BLDG-ID al que hace referencia BVILDING
BVILDING [ BLDG-ID, DIRECCIÓN, TIPO, NIVEL DE CANTIDAD, ESTADÍSTICAS]
HABILIDAD [ TIPO DE HABILIDAD, TASA DE BONIFICACIÓN, HORAS POR SEMANA]
Tupla, relación. Una tupla correspondiente a un esquema de relación dado es un conjunto de pares (nombre de atributo, un valor que contiene una ocurrencia de cada nombre de atributo que pertenece al esquema de relación. "Valor" es un valor de dominio válido para el atributo dado (o tipo de datos si no se admite la noción de dominio), por lo que el grado o "aridad" de una tupla, es decir, el número de elementos que la componen, coincide con la "aridad" del esquema de relación correspondiente.
Actitud Es un conjunto de tuplas correspondientes al mismo esquema de relación. A veces, para no confundirse, dicen "esquema de relación" y "instancia de relación", a veces el esquema de una relación se llama título de la relación, y la relación como un conjunto de tuplas se llama cuerpo de la relación. De hecho, el concepto de esquema de relación se acerca más al concepto de tipo de datos estructurados en los lenguajes de programación. Sería bastante lógico permitir definir por separado un esquema de relación y luego una o más relaciones con ese esquema.
Sin embargo, este no es el caso de las bases de datos relacionales. El nombre de esquema de una relación en dichas bases de datos es siempre el mismo que el nombre de la relación de instancia correspondiente. En las bases de datos relacionales clásicas, después de definir el esquema de la base de datos, solo se cambian las relaciones de instancia. Pueden aparecer nuevas tuplas en ellos y las tuplas existentes se pueden eliminar o modificar. Sin embargo, muchas implementaciones también permiten cambiar el esquema de la base de datos: definir nuevos esquemas de relaciones y modificar los existentes. A esto se le suele llamar la evolución del esquema de la base de datos.
La representación cotidiana habitual de una relación es una tabla, cuyo título es el diagrama de la relación y las filas son tuplas de la relación de instancia; en este caso, los nombres de los atributos nombran las columnas de esa tabla. Por lo tanto, a veces dicen "columna de tabla", que significa "atributo de relación". Cuando lleguemos a los problemas prácticos de la organización de bases de datos relacionales y las herramientas de gestión, usaremos esta terminología común. Esta terminología es utilizada por la mayoría de DBMS relacionales comerciales.
Una base de datos relacional es un conjunto de relaciones cuyos nombres son los mismos que los nombres de los esquemas de relaciones en el esquema de la base de datos.
Como puede ver, los conceptos estructurales básicos del modelo de datos relacionales (aparte del concepto de dominio) tienen una interpretación intuitiva muy simple, aunque en la teoría de bases de datos relacionales todos están definidos de manera absolutamente formal y precisa.
Clave de la tabla de relaciones. Las tuplas no deben repetirse en el interior. tablas de relaciones y, en consecuencia, deben tener un identificador único - Clave primaria. Uno o más atributos cuyos valores identifican de forma exclusiva una fila de la tabla son llave mesas.
La clave primaria se llama sencillo , cuando consta de un atributo, o compuesto, cuando consta de múltiples atributos. Además de la clave principal, la relación también puede contener claves secundarias.
Clave secundaria – es una clave cuyos valores se pueden repetir en diferentes cadenas de tuplas. Se pueden utilizar para buscar un grupo de filas con el mismo valor de clave secundaria.
Llave externa - es un conjunto de atributos de una tabla que es la clave de otra (o la misma) tabla. Las claves externas proporcionan relaciones importantes entre tablas. Se utilizan para vincular datos de una tabla con datos de otra tabla. Los atributos de clave externa no tienen que tener los mismos nombres que los atributos de clave a los que corresponden.
Información similar.
BASE DE DATOS RELACIONAL Y SUS CARACTERÍSTICAS. TIPOS DE RELACIONES ENTRE MESAS RELACIONALES
Base de datos relacional es una colección de tablas interconectadas, cada una de las cuales contiene información sobre objetos de cierto tipo. Una fila de la tabla contiene datos sobre un objeto (por ejemplo, un producto, un cliente) y las columnas de la tabla describen varias características de estos objetos: atributos (por ejemplo, nombre, código de producto, información del cliente). Los registros, es decir, las filas de una tabla, tienen la misma estructura: consisten en campos que almacenan los atributos de un objeto. Cada campo, es decir, una columna, describe solo una característica de un objeto y tiene un tipo de datos estrictamente definido. Todos los registros tienen los mismos campos, solo que muestran diferentes propiedades de información del objeto.
En una base de datos relacional, cada tabla debe tener una clave principal: un campo o combinación de campos que identifique de forma única cada fila de la tabla. Si una clave consta de varios campos, se denomina clave compuesta. La clave debe ser única e identificar de forma exclusiva la entrada. El valor de la clave se puede utilizar para buscar un solo registro. Las claves también se utilizan para organizar la información en la base de datos.
Las tablas de bases de datos relacionales deben cumplir los requisitos de normalización de relaciones. La normalización de relaciones es un aparato formal de restricciones en la formación de tablas, que elimina la duplicación, asegura la consistencia de las almacenadas en la base de datos y reduce los costos laborales para mantener la base de datos.
Deje que se cree la tabla de Estudiantes, que contiene los siguientes campos: número de grupo, nombre completo, número de estudiante, fecha de nacimiento, clasificación de especialidad, nombre de la facultad. Tal organización de almacenamiento de información tendrá una serie de desventajas:
- duplicación de información (se repite el nombre de la especialidad y facultad para cada alumno), por lo tanto, aumentará el volumen de la base de datos;
- El procedimiento para actualizar la información en la tabla es difícil debido a la necesidad de editar cada registros de la tabla.
La normalización de tablas está destinada a abordar estas deficiencias. Hay tres formas normales de relación.
Primera forma normal. Una tabla relacional se reduce a la primera forma normal si y solo si ninguna de sus filas contiene más de un valor en cualquiera de sus campos y ninguno de sus campos clave está vacío. Entonces, si de la tabla de Estudiantes se requiere obtener información por el nombre del estudiante, entonces el campo del nombre completo debe dividirse en partes: Apellido, Nombre, Patronímico.
Segunda forma normal... Una tabla relacional se especifica en la segunda forma normal si cumple con los requisitos de la primera forma normal y todos sus campos que no están incluidos en la clave principal están completamente relacionados funcionalmente con la clave principal. Para llevar la tabla a la segunda forma normal, es necesario determinar la dependencia funcional de los campos. La dependencia funcional de los campos es una dependencia, cuando en la instancia del objeto de información, solo un valor del atributo descriptivo corresponde a un cierto valor del atributo clave.
Tercera forma normal. Una tabla está en la tercera forma normal si satisface los requisitos de la segunda forma normal, ninguno de sus campos no clave depende funcionalmente de ningún otro campo no clave. Por ejemplo, en la tabla de Estudiantes (número de grupo, nombre completo, número de libro de calificaciones, fecha de nacimiento, starosta), tres campos: número de libro de calificaciones, número de grupo, starosta están en una relación transitiva. El número de grupo depende del número del libro de calificaciones y el director depende del número de grupo. Para eliminar la dependencia transitiva, es necesario transferir parte de los campos de la tabla Student a otra tabla, Group. Las tablas tendrán la siguiente forma: Alumno (número de grupo, nombre completo, número de libro de calificaciones, fecha de nacimiento), grupo (número de grupo, director).
Las siguientes operaciones son posibles en tablas relacionales:
- Concatenación de tablas con la misma estructura. El resultado es una tabla común: primero el primero, luego el segundo (concatenación).
- Intersección de tablas con la misma estructura. Resultado: se seleccionan los registros que están en ambas tablas.
- Resta de tablas con la misma estructura. Resultado: se seleccionan los registros que no se encuentran en la resta.
- Muestra (subconjunto horizontal). Resultado: se seleccionan registros que cumplen determinadas condiciones.
- Proyección (subconjunto vertical). El resultado es una relación que contiene algunos de los campos de las tablas originales.
- Producto cartesiano de dos tablas Los registros de la tabla resultante se obtienen combinando cada registro de la primera tabla con cada registro de la otra tabla.
Las tablas relacionales se pueden relacionar entre sí, por lo tanto, los datos se pueden recuperar de varias tablas al mismo tiempo. Las tablas están vinculadas entre sí para reducir en última instancia el tamaño de la base de datos. La relación de cada par de tablas está asegurada si tienen las mismas columnas.
Existen los siguientes tipos de enlaces de información:
- doce y cincuenta y nueve de la noche;
- uno a muchos;
- muchos a muchos.
Comunicación uno a uno asume que un atributo de la primera tabla coincide solo con un atributo de la segunda tabla y viceversa.
Relación uno a muchos asume que un atributo en la primera tabla corresponde a varios atributos en la segunda tabla.
Relación de muchos a muchos asume que un atributo de la primera tabla corresponde a varios atributos de la segunda tabla y viceversa.