The rapid evolution of software has led to an ever-increasing increase in the requirements for the computer disk subsystem. In addition to the speed of operation and the amount of information stored, manufacturers focused on improving such parameters as the reliability of drives and their consumer characteristics (for example, ease of installation and noise level). The rise in popularity of portable computers has directed the flow of engineering thought into the area of miniaturization of drives and increasing their reliability in extreme conditions. It is theoretically possible to develop a solution that simultaneously satisfies all the mentioned requirements. However, from a practical point of view, a universal solution will bring little joy, since an “ideal” hard drive will cost many times more than an “imperfect” one. It is for this reason that we are currently seeing a genuine variety of hard drives made using different technologies, connected through different interfaces and having different technical characteristics. This article provides brief advice on choosing hard drives, and also discusses the current problems that users and system administrators face in practice when implementing RAID arrays.
Some requirements for a modern hard drive
The hard drive (hard drive) is considered to be the most recognized and widespread means of storing information. The information on this drive does not disappear when the computer's power is turned off, unlike, say, RAM, and the cost of storing a megabyte of information is extremely small (about 0.6 cents). A modern hard drive has high performance and impressive capacity at a low cost per megabyte of disk memory. Modern hard drives can be 47 GB or larger. To "feel" such a volume, you can make a simple estimate. About 7 million ComputerPress magazine pages in text format, or almost 57,000 unique magazine issues, can be stored on a 47 GB disk. For this edition of ComputerPress, it would take almost 5 thousand years to work without failures. Hard drives (usually several, extremely rarely one) with a high-quality magnetic coating rotate inside the sealed casing of the hard drive at a huge constant speed (5400, 7200, 10,000, 15,000 rpm). They are "strung" on a rotating shaft - a spindle. Information on the disk is located on "tracks" (concentric circles), each of which is divided into pieces-sectors. Each area of the disk is assigned a corresponding number through a low-level formatting process performed by the drive manufacturer. Reading and writing on both sides of the magnetic disk is done using magnetic heads. The heads themselves are mounted on a special lever (adjucator) and are carried over the surface of a rotating disk at a speed indistinguishable by the human eye. The average time for which the head manages to settle down over the desired area of the disk (average access time) essentially reflects its performance - the shorter the access time, the faster the hard drive. In addition to the above, the hard drive includes a controller board containing all the drive electronics.
A modern hard drive, according to the PC'99 specification, must support bus mastering mode, as well as S.M.A.R.T. Bus mastering is a mechanism for direct exchange of information over the bus without the participation of the central processor. In addition to improving performance, this mode reduces the load on the central processor (there are already many contenders for its resources: lazy soft modems, sound cards, simultaneously running applications, etc.). To implement the bus mastering protocol, it is necessary that all participants in the process (including the hard disk controller and the motherboard chipset) support it. S.M.A.R.T. technology (Self-Monitoring Analysis and Reporting Technology) is a hardware mechanism for predicting failures on the hard drive, which guarantees users from "surprises" of the hard drive. Modern hard drives with an ATA (IDE) interface must support the Ultra ATA/33 mode, which provides peak external performance of the hard drive up to 33.3 MB/s. Many drives are already produced with the Ultra ATA/66 interface (maximum transfer rate is 66.6 MB/s), but, unfortunately, these figures are rarely achieved in reality, since the performance of hard drives is limited not by the narrowness of the data transfer interface, but mainly by mechanics.
The high speed of rotation of disks inside the hard drive leads to vibration, which is unacceptable and is damped by special design devices. That is why the design perfection of a hard drive can often be determined by ear: the quieter the hard drive, the better its mechanics and less heat.
Buying a hard drive: what to look for
When buying a hard drive in the price list of a trading company, you can usually find the following line: HDD IBM 13.7 GB 5400 rpm IDE ATA/66. This is translated into Russian as follows: a hard drive manufactured by IBM, with a capacity of 13.7 GB, a spindle speed of 5400 rpm with an Ultra ATA / 66 interface. It looks incomprehensible only at first glance. In fact, the principles for choosing a hard drive are universal:
- an authoritative trademark is not a guarantee of quality, but an argument in favor of choosing a branded hard drive. First of all, take a closer look at models from IBM and Seagate, although they, like any company, have successful and extremely unsuccessful series of hard drives;
- the higher the capacity, the more profitable the hard drive becomes in terms of "price per megabyte". However, high-capacity hard drives often become a dump of forgotten files, and are more expensive than their less capacious counterparts. Large hard drives take much longer to service (for example, defragment), so for home purposes, hard drives with a capacity of about 10-20 GB can be recommended;
- the higher the drive spindle speed, the greater its performance (speed of writing and reading data), but the higher the price and the stronger the heat. For home and office use, we recommend giving preference to hard drives with a spindle speed of 5400-7200 rpm (revolutions per minute - revolutions per minute);
- IDE (ATA) is a type of interface (mechanism and connection protocol) of a drive to a computer motherboard. The IDE interface is the cheapest and most common, so it can be a universal recommendation. More "professional" is the SCSI interface, which allows you to connect up to eight devices and IEEE-1394 (FireWire). SCSI has become noticeably less widespread than IDE due to its high price and configuration features. And FireWire should soon become the standard for digital data exchange between digital consumer electronics and computer peripherals. In a word, if you are not engaged in video editing, video digitizing and editing huge files, then your choice is a hard drive with an IDE interface;
- ATA / 66 (the same Ultra ATA 66 or Ultra DMA 66) is an extension of the IDE (ATA) interface, which allows, in exceptional cases, to achieve a data transfer rate of 66 MB / s and often reduce the load on the central processor. This, of course, is extremely rare and lasts a matter of fractions of a second. The usual performance of a hard drive is 4-5 times lower. In order for the disk subsystem to develop such performance, it is necessary that the motherboard controller and the hard drive support this standard. Modern hard drives are already available with ATA-100 support and are not much more expensive than analogues with ATA/33 or ATA/66. Conclusion: if finances allow, it is preferable to purchase an ATA-100 hard drive, but ATA/66 is a quite good choice as well.
Disk Subsystem Optimization Considerations
A high-speed hard drive does not yet guarantee you the maximum performance of the disk subsystem. Just as the retinue plays the king, the performance of a hard drive depends on the devices in which it is forced to work. First of all, it is necessary to balance needs and opportunities. In practice, this means that before buying a hard drive, you must absolutely know the capabilities of your motherboard. The purchase of an ATA-100 drive for an ATA-33/66 motherboard should be carefully thought out and justified - this is necessary first of all for you. Unfortunately, it is not uncommon (especially in an academic environment) when ATA-100 drives (7200 rpm) were purchased to update long-outdated i486/P60 drives. There is no need to talk about the financial or practical feasibility of this decision. However, we will not focus on the obvious, but consider little-known factors that affect the speed of the disk subsystem.
Two ATA devices on one cable: good or bad? Definitely bad! And this is caused not only by the fact that the same physical loop serves as the transport medium for both devices. The problem is somewhat different - in the way the controller works with each device, in which their parallel operation is impossible. In other words: until the first device has executed the command, it is impossible to access the second one. This means that if a slower device in the bundle is accessed, the faster one will have to wait for the previous operation to finish, which can significantly slow down its operation. This is most clearly seen in the example of the "hard drive-CD-ROM drive" bundle. That is why it is recommended to distribute ATA devices on different loops depending on their speed.
Using the bus mastering mode. The very first adopted ATA standard assumed the use of a central processing unit (CPU) of a computer to organize work with information storage devices. This was the PIO (programmed input/output) mode, which all ATA devices must still support. At the same time, the shortsightedness of this method, which consumed valuable processor resources for working with ATA devices, was quite obvious. Therefore, equipment manufacturers have proposed an alternative - the Bus Mastering mode (another name is DMA / UDMA). The main difference of the new mode was the release of the CPU from data transfer control operations and the delegation of these functions to the ATA controller. As a result, CPU power is released for more important operations, which allows you to increase the throughput of the disk subsystem. This mode has been supported without problems by all motherboards for more than five years.
Using a RAID controller. The main complaints about hard drives are their small volume and constantly insufficient speed. This is true for hard drives installed both on servers and workstations. However, if the proposal to upgrade the server disk subsystem still has a chance to be approved by the management, then complaints about the insufficient speed of the hard disk on the workstation with a 99.9% probability will die before reaching the ears of your system administrator. With a home computer, the situation is even more dramatic, since the money for updating the disk subsystem will have to be withdrawn from the family budget. At the same time, high-speed hard drives (ATA-100, 7200 rpm) currently cost about $130 for 20 GB. The way out of the impasse can be the use of a RAID controller, which allows you to combine several physical disks into one logical one. In a nutshell, the principle of using RAID is to parallelize read / write information streams between several physical media. As a result, the maximum read / write speed from the "combined" media increases as many times as the number of physical drives used to create the RAID array. The above is true only for zero-level RAID arrays, which do not imply duplication of stored information. In the past, RAID arrays used fairly expensive SCSI hard drives. But for about a year now, cheap (from $36) RAID controllers for hard drives with an IDE interface have been available on the market. In addition, some motherboard manufacturers (Abit, MSI, etc.) install RAID controllers on their motherboards along with standard IDE interfaces. The most common models of RAID controller cards for ATA hard drives in our market are Promise and Abit Hot Rod. Naturally, they are not the only ones. In particular, American Megatrends, Inc. (AMI), better known as a manufacturer of RAID controllers for SCSI hard drives, has turned its attention to this market segment with the release of the AMI HyperDisk ATA-100 RAID (estimated price of $120). As a result, at any time we have the opportunity to increase the speed of our disk subsystem without the need for large expenditures. In order for the situation with RAID not to seem so optimistic, let's add a fly in the ointment to a barrel of honey: a number of RAID controllers have serious problems, the nature of which is still unknown. For example, we are talking about the problem of compatibility of IBM DTLA - 3070xx hard drives and RAID controllers built on the HighPoint HPT-366/368/370 chipset. This problem has been actively discussed in Internet forums for several weeks. Its essence lies in the fact that in the case of creating a RAID array using a RAID controller based on the HPT - 366/368/370 chipset based on IBM DTLA-3070xx hard drives, unpredictable "shedding" of data occurs and a large number of bad blocks appear even on new hard drives. Judging by user feedback, this problem did not affect users of Promise products, but owners of Abit Hot Rod and motherboards with an integrated HPT-370 controller (reliably confirmed on Abit VP6 and Abit BX-133 RAID boards) fully felt it. The nature of this phenomenon has not yet received an official explanation, however, doubts are being expressed about the correct shutdown of the hard drives included in the array when the computer is shut down. As a result, data from the hard drive cache is not saved to media, which violates the integrity of the data. In this case, if the RAID controller is used as a source of additional ATA-100 ports (that is, the RAID function is not used), this problem does not occur. The most annoying thing is that some of the best representatives of the ATA-100 family of hard drives (DTLA - 3070xx series) are subject to this effect, since there are no reports of similar cases with hard drives from other manufacturers.
Some observations on the organization of RAID arrays from ATA drives
This section presents a number of reliable observations of the authors in the process of creating a backup server, as well as preliminary conclusions that were made based on them.
Situation one: Abit VP6 Dual PIII - 667 is used with four IBM DTLA-307045 in one RAID array. The first month everything works without problems. Approximately in the middle of the fifth week, a spontaneous (in one day) "shedding" (the appearance of bad blocks) of the entire array occurs. The array was disassembled, and by performing checks on all drives individually, a huge number of bad blocks (~ 3%) were found on each hard drive. Interestingly, the pattern of their location was repeated for each pair of drives. Conclusion: the problem of joint interaction of HPT-370 with IBM DTLA-3070xx is not solved by the latest versions of firmware and drivers.
Situation two: everything is the same, only AMI HyperDisk 100 is used instead of the built-in RAID controller. In addition, failed IBM disks are replaced with two Fujitsu hard drives and two Quantum hard drives connected to the first and second controller channels, respectively. It was supposed to organize two RAID arrays based on each pair of hard drives. All hard drives are installed in rack modules connected to the RAID controller via ATA-100 (80-pin) cables. After manually creating two arrays, we noted the appearance of two new disks of the expected size (MS Windows 2000 OS). After that, when formatting with an attempt to write data, the operating system hung. Remembering that in the rack-module the connection of hard drives goes through the ATA-33 cable (in this case, the controller indicated the mode of operation with UDMA-5 hard drives), we replaced the connecting cables with ATA-33. After such a replacement, the controller began to display a warning at each boot about the inevitable speed increase that awaits us when replacing the loops. Ignoring this invitation with deep regret, we noted the beginning of the normal operation of one pair of drives. However, the connection of the second pair brought a surprise - the created drive turned out to be impossible to format using Windows 2000, because at the end of formatting the OS reported that formatting could not be continued. After experiencing a moment of weakness, we closely studied the documentation on HyperDisk, especially the section on automatic creation of arrays. As a result, the first set of arrays was destroyed and the second one was created automatically. And then the surprises began. First of all, the controller combined hard drives from different manufacturers into one array, that is, instead of tandems by manufacturers, we got mixed tandems. It looked strange against the background of calls to use the same hard drives when creating arrays. The reason why pairs of drives were combined into a stripe array, and not all four at the same time, also remained unclear. A study of the current configuration established its full performance. However, since the volumes of Fujitsu and Quantum hard drives differed (as a result of asymmetrical merging, about 200 MB were lost per array), we continued to try to symmetrically combine hard drives. After a short but close study of the array configuration, it was noticed that each pair of hard drives included in its composition is physically connected to different channels of the RAID controller. Remembering the fact that the ATA controller is not able to work in parallel with devices connected to one of its channels, and that the use of an array involves simultaneous recording to each device included in its composition, we made a preliminary conclusion about the problematic operation of the array when connecting the drives that form it one ATA channel. This assumption provided a reasonable explanation for the fact that four hard drives were combined into two arrays (and not into one), which was automatically performed by the AMI HyperDisk controller. The logical conclusion from this assumption was to change the disk configuration in such a way that the Primary Master - Secondary Slave and Secondary Master - Primary Slave bundles were formed by hard drives from the same manufacturer. After reconnecting the drives, the arrays were automatically reconfigured, which brought the expected result - two arrays consisting of drives from the same manufacturer. As a result, we got back more than 200 "cut down" megabytes of the array. However, our joy faded when the operating system found only one (smaller) array. At the time of signing the issue, all attempts to force the operating system to "see" the array were unsuccessful, which can serve as another proof of the need to use exactly the same disks in the process of creating arrays.
ComputerPress 4 "2001
The disk subsystem of a computer as an important tool for processing raster graphics. Which option is faster?
In prepress imaging workflows, computer performance plays an important role. First, there are certain minimum system requirements for professional graphics work. So, for example, it is almost impossible to prepare a high-quality full-color layout of a printed publication using a 14-inch monitor and a video card that is unable to display 24-bit color. Second, just because your work platform meets these minimum requirements doesn't mean you'll be comfortable working with large graphics files. To increase the efficiency of working with a computer, it must have a margin of performance. This allows you to perform even resource-intensive operations (scaling, applying filters to an image, etc.) quickly enough, and ideally - in real time. A considerable contribution to the overall performance of the graphics station is made by its disk subsystem. It becomes a "bottleneck" of the system when processing files, the volume of which is comparable to the amount of RAM on the computer.
The situation with hard drives for the Wintel platform has always looked like this: there were SCSI hard drives targeted at the Hi-End sector of the market, and in parallel, less expensive IDE options were offered for installation in other systems. Over the past couple of years, there has been a real technological breakthrough in the field of IDE drives - suffice it to say that if at the end of 1998 a 4.3 GB hard drive was considered average in all respects, with a spindle speed of 5400 rpm and recording density 2 GB per platter, in late 2000, 40-45 GB / 7200 rpm / 15-20 GB per platter falls into the middle category. In this case, the use of the ATA-100 standard and the reduction of the noise of a working disk to values of the order of 30 dB becomes the norm.
In the field of SCSI hard disks, such a jump in performance was not observed - until now, the average capacity for disks of this standard is at the level of 18 GB with a recording density of about 6 GB per platter. The superiority in performance over IDE drives is maintained due to other important parameters - a high spindle speed (10,000 rpm are the norm), a large amount of built-in buffer (from 4 to 8 MB versus 0.5-2 MB for IDE models) , and also largely due to the peculiarities of SCSI technologies in general.
However, modern IDE hard drives are literally stepping on the heels of their expensive SCSI counterparts. The most weighty arguments in favor of the IDE-version of the disk subsystem of your computer are extremely low price (2-4 times less than that of SCSI) with high capacity, low heat dissipation and noise level.
The situation is further aggravated by the fact that IDE-standard RAID arrays have become popular recently. Prior to this, RAID technologies were used mainly for SCSI disk subsystems. The appearance on the market of relatively inexpensive IDE RAID controllers allowed IDE hard drives to further expand their market niche. The RAID 1 (Mirror) standard allows you to increase the reliability of the disk subsystem in proportion to the number of redundant hard disks. So, by building a RAID array in Mirror mode from two identical hard drives, we double the reliability of storing our information (it is duplicated) and at the same time get a nice bonus in the form of a slightly increased read speed from the disk array (this is possible due to sequential reading of blocks of information from two hard drives and organizing it into a single stream; this is done at the hardware level by the RAID controller). In the case of using RAID 0 (STRIPE mode), we get an increase in the speed of our disk subsystem in proportion to the number of disks that make up the array - the information is divided into small blocks and "scattered" over the disks. Thus, purely theoretically, it would be possible to increase the speed of the disk subsystem by a factor equal to the number of hard drives in the array. Unfortunately, in practice, the speed increase is not so significant, but you can read about it below by evaluating the test results. It is impossible not to note the main disadvantage of the RAID 0 (Stripe) mode - the reliability of information storage decreases exactly in the same number of times, which is equal to the number of hard drives used. The RAID 0 + 1 mode is designed specifically to eliminate this unpleasant effect - a kind of "mixture" of the Mirror and Stripe modes. A RAID 0+1 array requires at least 4 hard drives. The result is single drive reliability plus double the capacity and increased performance.
The performance of various types of hard drives is often confusing for many users. Most people only know that "SCSI is terribly cool, much faster than IDE", some of the "advanced" sincerely believe that a RAID array of two disks in Stripe mode is exactly twice as fast as a single hard drive. In fact, many myths have developed in this area, often completely incorrect. This article is an attempt to clear things up by accurately measuring the performance of different types of disk subsystems. I would like to pay special attention to the fact that not synthetic test suites (which, as a rule, are of little use) were used to evaluate performance, but the most practical tasks from the arsenal of people professionally involved in graphics on a PC.
So, the following variants of disk subsystems were tested:
| IDE- outdated hard drive (5400 rpm, 512 kb cache, 4 GB per platter) with ATA-33 interface - Fujitsu MPD3130AT; motherboard - i440BX with built-in ATA-33 controller. |
| IDE- new series hard drive (7200 rpm, 2048 KB cache, 20 GB per platter) with ATA-33 interface - Western Digital WD200; i440BX, ATA-33 (embedded). |
| IDE- new series hard drive (7200 rpm, 2048 KB cache, 20 GB per platter) with ATA-100 interface - Western Digital WD200; Promise FastTrak100 (SPAN) RAID controller. |
| RAID-an array of two modern IDE drives in Stripe mode - 2xWestern Digital WD200; Highpoint Technologies HPT370 UDMA/ATA 100 Raid Controller (STRIPE). |
| SCSI- high-end hard drive (10,000 rpm, 4096 KB cache, 6 GB per platter) with SCSI Ultra160 interface - Fujitsu MAJ 3182 MP; SCSI controller - Adaptec 29160N. |
For the purity of the experiment, each version of the disk subsystem was installed in the system absolutely "from scratch". The disk (or disk array) was divided by the FDISK program into three logical ones. In this case, the size of the boot partition (logical drive C:\) was always set to 3 GB. The rest of the space was divided equally between the D:\ and E:\ drives. The operating system was installed on the C:\ drive, the Photoshop paging file was located on the D:\ drive; there were also test files. The file system is FAT32.
In order to give a good load on the disk subsystem and thus evaluate its performance, the amount of RAM was limited to 128 MB (despite the fact that in systems of this class designed to work with raster graphics, 256 MB are the entry level). The amount of memory available to Photoshop 5.5 was set to 50% of the total free memory. This volume was approximately 57 MB. All tests were run with two files of different sizes - the size of the first was 1/5 of the amount of memory available to Photoshop, the size of the second was 1.5 times larger (). This made it possible to obtain data on the speed of performing a particular operation in two cases: when the file being processed fits in RAM with a margin, and when it is guaranteed not to fit there in its entirety. I must say that for a file of a smaller size, the results obtained on different disk subsystems are almost identical, which is not at all surprising - the main processing took place in RAM. Differences in this case are noticeable only in read / write operations - when opening and saving a file. A completely different picture was observed when processing a large file. Since the file did not fit entirely in RAM, Photoshop actively used the computer's disk subsystem. The results of these tests, as the most revealing, are presented in the form of diagrams. The full results, including tests with a smaller file size as well as with a more powerful processor, can be seen in summary table #2.
Those interested can repeat all the tests in this article on other systems, since all the settings used are listed in the table. The test files were created as follows: CMYK balloons.tif was taken from the ... \Adobe\Photoshop5.5\Goodies\ Samples\ directory. After converting to RGB, it was scaled up to 2240x1680 and 6400x4800 pixels, resulting in two TIFF RGB files of 10.7 and 89.7 MB, respectively. All operations were carried out on the received files. After each operation, the result was canceled by the Undo command. The last operation (Save) was performed in CMYK format. Each test was run three times and the results were averaged. After each test, the system rebooted.
System #1: Fujitsu MPD3130AT; i440BX, ATA-33
The Fujitsu MPD series hard drive is a well-deserved veteran. A year and a half ago, hard drives of such a class as Fujitsu MPD, Quantum CR and their other analogues were the fastest in the IDE standard hard drive sector. This hard drive has three 4.32 GB platters, 6 read/write heads and a built-in 512 KB buffer. Average seek time - 9.5 / 10.5 ms (read / write), spindle speed - 5400 rpm, noise level - 36 dB. The ATA-66 standard is supported, but this is nothing more than a marketing ploy, since the data transfer rate is in the range of 14.5-26.1 MB / s, which fully fits into the capabilities of the ATA-33 standard (33.3 MB / s) .
The Fujitsu MPD3130AT proved to be a reliable, quiet hard drive. During operation, the noise of a rotating spindle is almost inaudible, but the sound of positioning heads is clearly distinguishable. The disk heats up very little - even with prolonged use, the case remains cool or barely warm.
In tests, the MPD3130AT significantly loses to all other participants, which is not at all surprising, given the difference in characteristics with the closest competitor WD200 (rotation speed - 5400 and 7200 rpm, respectively, recording density - 4.3 GB per platter versus 20 GB).
Testing on two different operating systems has yielded somewhat conflicting results: Windows 98 is much faster than file open and save operations, while Windows 2000 is much faster than everything else. Otherwise, no surprises.
System #2: Western Digital WD200; i440BX, ATA-33.
WD200 is a representative of a new generation of hard drives. The main parameters are 7200 rpm, the internal cache increased to 2048 KB, the recording density is 20 GB per platter. The disc has one platter and two heads. The average seek time is declared by the manufacturer as 8.9/10.9 ms, which is not very different from the characteristics of the Fujitsu MPD3130AT. However, the WD200 is noticeably faster. First, the bigger volume of the built-in buffer affects. Secondly, the exchange rate in the "buffer-to-surface" section reaches an impressive 30.5-50 MB/s - after all, 20 GB per platter is a serious recording density.
In operation, the disk proved to be very positive - despite the increased spindle speed, it turned out to be quieter than the Fujitsu MPD (declared noise level - 30 dB). Head movements are almost inaudible.
With heat dissipation, things are worse, but quite acceptable. After an hour of intensive work, the hard drive heated up to 45 degrees, i.e. felt warm to the touch, but not hot.
In general, this configuration left a very favorable impression and is the undisputed champion in terms of price-performance ratio. Judge for yourself - at a price of about $130 this hard drive forms a complete solution with an integrated ATA-33 controller of the 440VX chipset. And no problems with Windows 98, as is observed in the case of using the ATA-100.
System #3: Western Digital WD200; ATA-100 Promise FastTrak100 (SPAN).
The tests revealed a very interesting point - when using the ATA-100 interface in Windows 98, the performance of the disk subsystem was in most cases lower than when using the ATA-33. And in some cases, there was just a catastrophic (5-10 times) performance drop! Since the results in Windows 2000 were absolutely predictable (that is, the ATA-100 turned out to be faster than the ATA-33, as expected), this gives reason to suspect that the Windows 98 + ATA-100 combination is not working correctly. Perhaps the reason lies in the specific model of the controller - Promise FastTrak100. In addition, most of the tests ran faster on Windows 2000.
From all this we can draw a logical conclusion - Windows 98 is not suitable for serious work with graphics. If you want to use the latest developments in the field of IDE, namely the ATA-100 interface or a RAID array in STRIPE mode, it is better to work with NT family operating systems (Windows NT 4.0 or Windows 2000), which behave more correctly in such modes.
When using Windows 2000, there is a gain from switching from ATA-33 to ATA-100, but it is not large.
System #4: Two Western Digital WD200 + HPT370 UDMA/ATA 100 Raid Controller(STRIPE) drives.
And, finally, a RAID array of two identical hard drives was tested in striped data blocks (STRIPE) mode. A block size of 64 KB was used as the most optimal (according to other independent tests). Theoretically, the speed of such a disk subsystem can be 2 times higher than that of a single disk. But the test results leave no reason for optimism. In the vast majority of tasks, the performance gain is 5-15% compared to a single drive with an ATA-100 interface.
In a word, the results are disappointing. Building a RAID 0 array can only be recommended to those who want to get the maximum performance out of IDE technology, despite all the disadvantages described above. But this may be necessary only for those who are engaged in inputting uncompressed video on a PC.
System #5: Fujitsu MAJ 3182 MP + Adaptec 29160N SCSI controller.
The last participant in the "competition" is a very high class SCSI hard drive. I must say that MAJ 3182 was chosen as the "top bar" of this test. Well, this hard drive managed to demonstrate its superiority clearly - in almost all tests it goes "head to head" with its main rival - a RAID array in STRIPE mode.
An idea of the potential capabilities of Fujitsu MAJ 3182 MP can also be given by its characteristics. Spindle speed - 10,025 rpm, number of disks - 3, heads - 5, average seek time - 4.7 / 5.2 ms, built-in buffer size - 4096 KB. The SCSI Ultra160 interface is used, which provides a synchronous data transfer rate in the "buffer-controller" section of 160 MB / s.
All these impressive parameters affected the power consumption and noise of the hard drive. The Fujitsu MAJ 3182 MP heats up just terribly - the case temperature rises to 60°C after a long period of operation, if not more - the case clearly burns fingers. The noise level during operation is also not small - 40 dB. And the biggest downside is the price. At the time of this writing, a set of a hard drive and a SCSI-160 controller cost about $500 in Moscow.
Results
So, based on the test results, I would like to draw a few conclusions that will be useful to those who are going to upgrade the disk subsystem of their graphics station.
- Disks of previous generations with a low recording density and a small built-in buffer significantly lose to modern models in all main parameters - speed, capacity and noiselessness. Feel free to change an old Fujitsu MPD class hard drive for a new high-speed hard drive with increased recording density (15-20 GB per platter) and a large cache (2 MB). Performance gains can be 100 percent or more. Moreover, all of the above remains valid even when using the ATA-33 interface.
- Switching from ATA-33 to ATA-100 does not provide much performance gain. Buying a separate ATA-100 controller, albeit an inexpensive one (about $30), in my opinion is not worth it. A suitable option is the presence on the motherboard of a "free" built-in controller of this standard.
- The RAID array in STRIPE mode showed very good performance - at the level of SCSI ten-thousanders, and often even higher. At the same time, one must take into account the very attractive cost of such a configuration, because two hard drives that make up an array, together with an inexpensive RAID controller from Highpoint, cost less than one SCSI hard drive without a controller! (130+130+30 = $290). And on top of that, we get a huge, in comparison with the SCSI version, a capacity of 40 GB. The only, but very big minus is a decrease in the reliability of data storage by 2 times. However, if a disk array of this type will be used as a tool for operational work, and not as a long-term storage of valuable information, its acquisition is more than justified.
- Top-tier SCSI hard drives, as you would expect, have the highest performance.
However, given the high price, high heat dissipation and noise level of such devices, their purchase is justified only when you need uncompromisingly high performance (and reliability of the disk subsystem, because SCSI hard drives have always been famous for their reliability and high MTBF).
In conclusion, I would like to draw readers' attention to two lines in the last table - the results of measurements when replacing the Pentium-III-650E processor (100 MHz system bus) with Pentium-III-866EB (133 MHz FSB). As you can see, replacing the processor with a significantly more powerful one does not give a wide spread of results. This shows that the chosen testing method was correct (low "processor dependence", the main load falls on the disk subsystem).
WITH Andrey Nikulin can be contacted by email: [email protected] .
The editors would like to thank Elko Moscow, SMS, Pirit and Russian Style for their help, which provided the equipment for testing.
| Motherboard | ASUS P3B-F |
| CPU | Intel Pentium III-650E (FSB 100 MHz) |
| RAM | 128 MB, PC-133 M.tec (2-2-2-8-Fast) |
| Video adapter | Creative 3DBlaster TNT2 Ultra |
| RAID controller | Highpoint Technologies HPT370 UDMA/ATA 100 Raid Controller |
| ATA-100 controller | Promise FastTrak100 |
| SCSI controller | Adaptec 29160N (Single Channel 32-bit PCI-to-Ultra160 SCSI Host Adapter (OEM)) |
| Hard drives | IDE-Fujitsu MPD3130AT IDE - Western Digital WD200 - 2 pcs. SCSI - Fujitsu MAJ 3182 MP |
| Operating system | Windows 98 4.10.1998 + DirectX 7.0a Windows 2000 Professional 5.00.2195 Service Pack 1 |
| Test program (option settings) | Adobe Photoshop 5.5: Cache Settings: Cache Levels - 4 The Use cache for histograms option is enabled. Physical Memory Usage: Available RAM - 113,961 KB; Used by Photoshop - 50%; Photoshop RAM - 56,980 KB. Scratch Disks: First: D:\; the rest are disabled. |
| Test files | 0.2 Photoshop RAM; 2240x1680 pixels; 24-bit color; RGB TIFF, 10.7 MB; 1.5 Photoshop RAM; 6400x4800x24; RGB TIFF; 87.9 MB. |
Magazines in the public domain.
16.01.1997 Patrick Corrigan, Mickey Applebaum
Configuration options for server disk subsystems are diverse, and, as a result, confusion is inevitable. To help you understand this difficult issue, we decided to consider the main technologies and the economic feasibility of their application. DISC
Configuration options for server disk subsystems are diverse, and, as a result, confusion is inevitable. To help you understand this difficult issue, we decided to consider the main technologies and the economic feasibility of their application.
In the case of server disk subsystems, you have many options to choose from, but the plethora makes it difficult to find the system that works best for you. The situation is complicated by the fact that in the selection process you will have to deal with a considerable amount of false information and marketing hype.
The review of the main technologies of server disk subsystems and the discussion of the expediency of their use in terms of cost, performance, reliability and fault tolerance should help to understand the essence of this issue.
DISK INTERFACES
Whether you are specifying a new server or upgrading an existing one, the disk interface is a critical issue. Most drives today use SCSI or IDE interfaces. We will look at both technologies, describe their implementations, and discuss how they work.
SCSI is a standardized ANSI interface that has several variations. The original SCSI specification, now called SCSI-I, uses an 8-bit data channel at a maximum data rate of 5 Mbps. SCSI-2 allows several variations, including Fast SCSI with an 8-bit data channel and transfer rates up to 10 Mbps; Wide SCSI with 16-bit data channel and transfer rate up to 10 Mbps; and Fast/Wide SCSI with 16-bit data link and transfer rates up to 10 Mbps (see Table 1).
TABLE 1 - SCSI OPTIONS
| SCSI-1 | Maximum performance | Channel Width | Frequency | Number of devices* |
| 5 Mbps | 8 digits | 5 MHz | 8 | |
| SCSI-2 | ||||
| Fast SCSI | 10 Mbps | 8 digits | 10 MHz | 8 |
| Fast/Wide SCSI | 20 Mbps | 16 digits | 10 MHz | 8; 16** |
With the advent of "wide" 16-bit Fast/Wide SCSI, 8-bit versions have sometimes been referred to as "narrow" - Narrow SCSI. Several more SCSI implementations have recently emerged: Ultra SCSI, Wide Ultra SCSI, and SCSI-3. Compared to more common options, these interfaces have some performance advantage, but since they are not yet very widespread (the number of devices using these interfaces is very limited), we will not discuss them in this article.
The SCSI-I cable system is a line bus with the ability to connect up to eight devices, including a host bus adapter (HBA). This bus design is called single-ended SCSI SCSI, and the cable length can be up to nine meters. SCSI-2 (virtually replacing SCSI-I) supports both single-ended SCSI and differential SCSI. Differential SCSI uses a different signaling method than single-ended SCSI and supports up to 16 devices on a loop up to 25 meters long. It provides better noise suppression, which means better performance in many cases.
One problem with differential SCSI is device compatibility. For example, there are limited varieties of differential SCSI compatible tape drives and CD-ROM drives today. Differential devices and HBAs are usually slightly more expensive than single-ended devices, but they have the advantage of supporting more devices per channel, longer loops, and, in some cases, better performance.
When choosing SCSI devices, you should be aware of compatibility issues. Single-ended SCSI and differential SCSI can use the same wiring, but single-ended and differential devices cannot be combined. Wide SCSI uses a different cabling system than Narrow SCSI, so it is not possible to use Wide SCSI and Narrow SCSI devices on the same channel.
HOW SCSI WORKS
In SCSI, the device controller (for example, a disk controller) and the interface with the computer are different devices. The Computer Interface, HBA, adds an additional interface bus to the computer for connecting multiple device controllers: up to seven device controllers on a single-ended SCSI link and up to 15 on a differential link. Technically, each controller can support up to four devices. However, at the high transfer rates of today's high-capacity drives, the device controller is typically built into the drive to reduce noise and electrical noise. This means you can have up to seven drives on a single-ended SCSI link and up to 15 on a differential SCSI link.
One of the advantages of SCSI is the processing of multiple, overlapping commands. This overlapped I/O support gives SCSI drives the ability to fully mix their reads and writes with other drives in the system, so that different drives can process commands in parallel instead of one at a time.
Since all the intelligence of the SCSI disk interface resides in the HBA, the HBA controls OS access to the disks. As a result, the HBA, not the computer, resolves translation and device access conflicts. In general, this means that, provided that correctly written and installed drivers are used, the computer and OS do not see any difference between the devices.
In addition, since the HBA controls access between the computer's internal expansion bus and the SCSI bus, it can resolve access conflicts to both of them by providing advanced features such as a link break/restore service. Break/Recovery allows the OS to send a find, read, or write command to a specific device, after which the drive is left to itself to execute the command, so that another drive on the same channel can receive the command in the meantime. This process greatly improves the throughput of disk channels with more than two disks, especially when the data is striped or scattered across the disks. Another enhanced feature is synchronous data exchange, whereby the overall throughput of the disk channel and data integrity are increased.
IDE
IDE is the de facto standard widely used in x86 based PCs. This is just a general recommendation for manufacturers, so everyone was free to develop a specific IDE for their devices and adapters. As a result, products from different manufacturers, and even different models of the same manufacturer, turned out to be incompatible with each other. Once the specification has settled, this problem has almost disappeared, but incompatibility is still possible.
Unlike SCSI, IDE puts the intelligence on the disk rather than the HBA. The HBA for the IDE has little to no intelligence and simply directly outputs the computer's bus to the disks. Without an intermediate interface, the number of devices on one IDE channel is limited to two, and the cable length is limited to three meters.
Since all the intelligence of IDE devices resides on the devices themselves, one of the devices on the channel is designated as the channel master, and the built-in controller on the second is disabled, and it becomes a slave (chanell slave). The master device controls access through the IDE channel to both devices and performs all I/O operations for them. This is one possibility of conflict between devices due to different vendor implementations of the IDE interface. For example, one drive may be designed to work with a particular controller scheme, but the host it is connected to may use a different controller type. In addition, the newer Enhanced IDE (EIDE) drives use an extended set of commands and translation tables to support larger capacity and higher performance drives. If they are connected to an old standard, IDE master drive, not only do they lose their advanced features, but they may not provide you with all of their available capacity. Worse, they can report their full capacity to the OS without being able to use it, potentially damaging the information on the disk.
The possibility of data corruption is due to the fact that each operating system perceives disk configuration information in its own way. For example, DOS and the system BIOS only allow a maximum disk capacity of 528 MB. NetWare and other 32-bit systems do not have these limitations and are able to read an entire IDE drive directly through its electronics. When you create multiple partitions of different operating systems on the same disk, each of them sees the capacity and configuration differently, and this can lead to overlapping partition tables, which, in turn, significantly increases the risk of data loss on the disk.
The original IDE architecture does not recognize drives larger than 528MB and can only support two devices per channel at a maximum transfer rate of 3Mbps. To overcome some of the limitations of the IDE, the EIDE architecture was introduced in 1994. EIDE supports higher capacity and performance, but its transfer rates of 9 to 16 Mbps are still slower than those of SCSI. Also, unlike 15 devices per channel for SCSI, it can support a maximum of four per channel. Note also that neither the IDE nor the EIDE provide multitasking functionality. And therefore, they cannot provide the same level of performance as SCSI interfaces in a typical server environment.
Although originally designed for disks, the IDE standard now supports tape drives and CD-ROMs. However, splitting a channel with a CD-ROM or tape drive can adversely affect disk performance. Overall, the performance and scalability advantages of SCSI make it a better choice than IDE or EIDE for most high-end server applications that require high performance. However, for entry-level applications where performance or extensibility is not a big deal, an IDE or EIDE will suffice. At the same time, if you need disk redundancy, then the IDE is not the best option due to the potential problems associated with the master-slave approach. In addition, you should be wary of possible partition table overlap and master-slave device incompatibility issues.
However, there are a few cases where the IDE and EIDE interfaces can be used in high end servers. It is common practice, for example, to use a small IDE drive for the DOS partition on NetWare servers. It is also widely practiced to use CD-ROM drives with an IDE interface for downloading software.
REDUNDANT DISK SYSTEMS
Another important issue to discuss when defining a server specification is redundancy. There are several methods to improve the reliability of a multi-disk disk system. Most of these redundancy schemes are variants of RAID (stands for "Redundant Array of Inexpensive or Independent Disks"). The original RAID specification was designed to replace large, expensive mainframe and minicomputer disks with arrays of small, cheap disks designed for minicomputers—hence the word "inexpensive." Unfortunately, you rarely see anything inexpensive in RAID systems.
RAID is a series of implementations of redundant disk arrays to provide different levels of protection and data transfer rates. Since RAID involves the use of disk arrays, SCSI is the best interface to use since it can support up to 15 devices. There are 6 RAID levels: from zero to fifth. Although some manufacturers advertise their own redundancy schemes which they refer to as RAID-6, RAID-7 or higher. (RAID-2 and RAID-4 are not on network servers, so we won't talk about them.)
Of all RAID levels, zero has the highest performance and least security. It assumes at least two devices and synchronized data writing to both disks, while the disks look like one physical device. The process of writing data to multiple disks is called drive spanning, and the actual method of writing this data is called data striping. With striping, data is written to all disks block by block; this process is called block interleaving. The block size is determined by the operating system, but typically ranges from 2 KB to 64 KB. Depending on the design of the disk controller and HBA, these sequential writes may overlap, resulting in increased performance. For example, RAID-0 on its own can improve performance, but it does not provide fault protection. If a drive fails, the entire subsystem fails, usually resulting in a complete loss of data.
A variant of data interleaving is data scattering. As with striping, data is written sequentially to multiple disks that fill up. However, unlike striping, it is not necessary to write to all disks; if the disk is busy or full, data can be written to the next available disk - this allows you to add disks to an existing volume. Like the RAID-0 standard, the combination of disk population with data striping improves performance and increases volume size, but does not provide failure protection.
RAID-1, known as disk mirroring, involves installing pairs of identical disks, with each disk in the pair being a mirror image of the other. In RAID-1, data is written to two identical or almost identical pairs of disks: when, for example, one disk fails, the system continues to work with a mirrored disk. If the mirrored disks share a common HBA, then the performance of this configuration, compared to a single disk, will be lower, since data must be written sequentially to each disk.
Novell narrowed down the definition of mirroring and added the concept of duplexing. According to Novell terminology, mirroring refers to disk pairs when they are connected to a server or computer via a single HBA, while duplication refers to mirrored disk pairs connected via separate HBAs. Redundancy provides redundancy for the entire disk channel, including HBAs, cables, and disks, and provides some performance gains.
RAID-3 requires at least three identical drives. This is often referred to as "n minus 1" (n-1) technology because the maximum system capacity is given by the total number of drives in the array (n) minus one drive for parity. RAID-3 uses a write method called bit interleaving, where data is written to all disks bit by bit. For each byte written on the n-disks, a parity bit is written to the "parity disk". This is an extremely slow process because before parity information can be generated and written to the "parity disk", data must be written to each of the n disks of the array. You can increase the performance of RAID-3 by synchronizing the disk rotation mechanisms so that they work strictly in step. However, due to performance limitations, the use of RAID-3 has dropped dramatically, and very few server products based on RAID-3 are sold today.
RAID-5 is the most popular implementation of RAID in the network server market. Like RAID-3, it requires at least three identical disks. However, unlike RAID-3, RAID-5 stripes data blocks without using a dedicated disk for parity. Both the data and the checksum are written over the entire array. This method allows independent reads and writes to the disk, and allows the operating system or RAID controller to perform multiple concurrent I/Os.
In RAID-5 configurations, the disk is accessed only when parity information or data is read/written from it. As a result, RAID-5 has better performance than RAID-3. In practice, the performance of RAID-5 can sometimes match or even exceed the performance of single disk systems. This performance improvement, of course, depends on many factors, including how the RAID array is implemented and what native capabilities the server operating system has. RAID-5 also provides the highest level of data integrity of any standard RAID implementation because both data and parity are written in striped form. Since RAID-5 uses block striping rather than bit striping, there is no performance benefit to spin synchronization.
Some manufacturers have added extensions to their RAID-5 systems. One of these extensions is the presence of a "hot-spare" disk built into the array. If a drive fails, the hot spare immediately replaces the crash drive and copies the data back to itself with parity recovery in the background. However, keep in mind that rebuilding a RAID-5 disk results in a serious drop in server performance. (For more information about hot-swap and hot-spare drives, see the sidebar "Hot" Drive Features.)
RAID systems can be organized both with the help of software loaded on the server and using its processor for operation, and with the help of a specialized RAID controller.
Software-implemented RAID systems take up a significant amount of system processor resources, as well as system memory, which greatly reduces server performance. Software RAID systems are sometimes included as a feature of the operating system (as is done with Microsoft Windows NT Server) or as a third-party add-on (as is done with NetWare and the Macintosh operating system).
Hardware-based RAID systems use a dedicated RAID array controller; it usually has its own processor, cache, and ROM software for disk I/O and parity. Having a dedicated controller to perform these operations frees up the server processor to perform other functions. In addition, because the processor and adapter software are specifically tuned for RAID functionality, they provide better disk I/O performance and data integrity than software-based RAID systems. Unfortunately, hardware-based RAID controllers tend to be more expensive than their software-based competitors.
MIRRORING, DUPLICATING AND FILLING
Some operating systems, including NetWare and Windows NT Server, allow disk mirroring across multiple disk channels, thus providing an additional layer of redundancy. As mentioned earlier, Novell calls the latter approach disk duplication. When combined with disk fill, duplication can provide better performance than single-disk systems and can generally outperform hardware RAID-5 implementations. Since each half of a mirrored pair of disks uses a separate disk channel, writes to disks, unlike the case when the disks are on the same HBA, can be written simultaneously. Also duplication allows split search - the process of dividing read requests between disk channels for faster execution. This feature doubles disk read performance as both channels search different blocks in parallel from the same data set. It also reduces the performance impact when writing to disk, since one channel can read data while the other writes.
NetWare supports up to eight disk channels (some SCSI adapters provide multiple channels), which means you can have multiple channels for each duplicated pair. You can even choose to organize up to eight separate mirror channels. Windows NT Server also provides software-based mirroring and duplication, but does not yet support parallel writes and separate seeks.
There are four main factors to consider when choosing a redundant disk system: performance, cost, reliability, and failure protection.
In terms of performance, the built-in capabilities of the server operating system are a major factor, especially when disk redundancy comes into play. As previously stated, NetWare disk duplication combined with disk fill gives better performance than hardware or software RAID. However, the performance of hardware RAID is generally superior to that of the built-in disk services of Windows NT Server. Generally speaking, over the years, the technology and performance of RAID systems have been constantly improving.
Another potential performance issue with RAID systems is data recovery in the event of a disaster. Until recently, if a drive failed, you had to turn off the RAID array to restore it. Also, if you wanted to change the size of the array (increase or decrease its capacity), you had to make a full backup of the system, and then reconfigure and reinitialize the array, erasing all data during this process. In both cases, the system is unavailable for quite some time.
To solve this problem, Compaq has developed the Smart Array-II controller, which allows you to expand the capacity of an array without reinitializing the existing array configuration. Other manufacturers, including Distributed Processing Technology (DPT), have announced that their controllers will perform similar functions in the not too distant future. Many of the new arrays have utilities for various operating systems that can be used to restore the array after replacing a damaged device without shutting down the server. However, keep in mind that these utilities eat up a lot of server resources and thus adversely affect system performance. To avoid this kind of difficulty, the restoration of the system should be carried out during non-working hours.
There have been numerous discussions in industry and RAID vendor publications about the difference in cost between mirroring, duplication, and RAID implementations. Mirroring and duplication give 100% doubling of disks and (if duplicated) HBAs, while RAID implementations have one HBA and/or RAID controller plus one disk more than the capacity you want to end up with. According to these arguments, RAID is cheaper because the number of disks required is less. This may be true if the performance limitations of the software RAID implementations included in the operating system, such as those found in Windows NT, are tolerable for you. In most cases, however, a dedicated RAID controller is needed to achieve adequate performance.
Drives and standard SCSI adapters are relatively inexpensive, while a high-quality RAID controller can cost up to $4,500. To determine the cost of your system, you must consider the optimal configurations for all components. For example, if you need approximately 16 GB of addressable disk space, you can implement a mirrored configuration with two 9 GB disks per channel and get some excess capacity. In the case of RAID-5, for performance and reliability reasons, it is better to stick with five 4 GB disks to increase the number of data striping spindles and thereby the overall performance of the array.
With an external disk subsystem, a mirror configuration will cost approximately $10,500 per 18 GB of available space. This figure is based on actual retail prices: $2000 for one drive, $250 for one HBA, and $300 for each external disk subsystem including cables. A RAID-5 system configured with 16 GB of addressable space using five 4 GB disks will cost about $12,800. This figure is based on actual retail prices for a DPT RAID-5 array.
Many RAID systems include "proprietary" components designed by the manufacturer. At a minimum, the "branded" are the case and the rear panel. HBAs and RAID controllers are also often proprietary. Some manufacturers also use non-standard holders and tires for discs. Someone provides them separately for a reasonable price, someone - only together with the disk and, as a rule, at a high price. The latter approach can be costly when you need to fix or expand your system. Another way the vendor drives you into a corner is by providing disk administration and monitoring software that only works with specific components. By avoiding non-standard components whenever possible, cost can usually be kept down.
When comparing the reliability of redundant disk systems, there are two factors to consider: the possibility of a system failure or the failure of any of its components, and the possibility of data loss due to component failure. (Unfortunately, RAID or mirroring cannot save you from the main cause of data loss - user error!)
P = t / Tc,
where t is the operating time and Tc is the combined time between failures of the components.
When running without failure for a year (8760 hours) and a Tc of a hypothetical disk of 300,000 hours, the probability of failure becomes 3%, or a little less than one in 34 cases. As the number of components grows, the probability of failure of any component increases. Both RAID and mirroring increase the chance of failure but decrease the chance of data loss.
Table 2, taken from the Storage Dimensions bulletin titled "Fault-Tolerant Storage Systems for Continuous Networking", shows the probability of failure calculated using the above formula versus the probability of data loss for four padded disks, a five-disk RAID array, and eight mirrored disks. (Assuming all drives are the same size and all three systems provide the same usable capacity. For a bulletin, visit the Storage Dimensions page: http://www.storagedimensions.com/raidwin/wp-ovrvw.html.)
TABLE 2 - FAIL PROBABILITY ESTIMATES
While mirroring combined with drive fill has a higher statistical probability of a disk failure, it also has a much lower probability of data loss if a disk fails. Also, with a properly designed redundant system, the recovery time can be significantly shorter.
This example does not take into account many factors. To get a statistically correct figure, the mean time between failures of all disk system components, including HBAs, ribbon cables, power cords, fans, and power supplies, must be calculated. Of course, these calculations only tell what can happen given the reliability of the proposed components, but it is not at all necessary that this will happen.
When choosing a disk system, you must clearly know which components are not duplicated. In RAID systems, this can include HBAs, RAID controllers, power supplies, power cables, and ribbon cables. One of the benefits of duplication with separate disk subsystems on each channel is the elimination of most of the single places where failures can occur.
CONCLUSION
In general, SCSI devices are a better choice for a server disk subsystem than IDE or EIDE drives. It's easy to get SCSI drives up to 9 GB per drive, while today's EIDE drives have a maximum capacity of about 2.5 GB. With multiple dual-link HBAs, the total SCSI capacity can easily exceed 100 GB, while the EIDE limit is 10 GB. SCSI also has better performance; moreover, SCSI does not suffer from the problems that the master-slave approach in IDE/EIDE entails.
If you need disk redundancy, there are several options. Novell NetWare redundancy combined with disk fill provides both excellent performance and failure protection. Hardware-based RAID is also a good choice, but typically has lower performance and higher cost. If you're using Windows NT and performance is important to you, then hardware RAID might be your best bet.
Patrick Corrigan is President and Senior Consultant/Analyst at The Corrigan Group, a consulting and training firm. He can be contacted at: [email protected] or via Compuserve: 75170.146. Mickey Applebaum is a Senior Network Consultant at GSE Erudite Software. He can be contacted at: [email protected]
INTRODUCING DISK SUBSYSTEM FUNCTIONS
"Hot" functions of disk subsystems
The terms hot-swap, hot spare, and hot-rebuild, widely used to describe the specific functions of disk subsystems, are often misunderstood.
"Hot Swap" is a feature that allows you to remove a failed disk from the disk subsystem without shutting down the system. Hot swap support is a hardware feature of your disk subsystem, not RAID.
In hot-swappable systems, hard drives are typically mounted on sleds that allow the ground pins between the drive and the chassis to stay connected longer than the power and controller lines. This protects the drive from damage from static discharge or electrical arcing between the contacts. Hot-swappable disks can be used in both RAID arrays and mirrored disk systems.
"Hot restore" refers to the system's ability to restore the original disk configuration automatically after a failed disk is replaced.
Hot spares are built into a RAID array and are typically left idle until they are needed. At some point after the hot spare replaces the failed drive, you must replace the failed drive and reconfigure the array.
A hot-swappable disk system with hot spare disks does not necessarily have the ability to be hot-recovered. "Hot Swap" simply allows you to quickly, safely and easily remove/install a drive. A "hot spare" would seem to provide a "hot rebuild" as it allows a failed drive in a RAID array to be replaced immediately, but the failed drive still needs to be replaced before a rebuild command must be given. Today, all RAID systems available on the PC platform require some level of user intervention to begin restoration of data - at least at the level of loading the NLM module on the NetWare server or pressing the start button in the NT Server application menu.
When we talk about disk subsystem resources, there are three of them: the amount of space, the read and write speed in MB / s, and the read-write speed in the number of input / output operations per second (Input / Output per second, IOPS, or simply I /O).
Let's talk about volume first. I will give considerations that should be guided by, and an example of the calculation.
Considerations are as follows:
Disk space is occupied by the virtual machine disk files themselves. Therefore, you need to understand how much space they need;
If we plan to use thin disks for all or part of the VM, then we should plan their initial volume and subsequent growth (hereinafter, thin disks mean the corresponding type of vmdk files, that is, the thin provisioning function in the ESX (i) implementation) The fact is that the thin provisioning functionality can be implemented on a storage system regardless of ESX(i), and I mean not the functionality of storage systems);
By default, for each VM, the hypervisor creates a paging file equal in size to its RAM. This paging file is located in the VM folder (default) or on a separate LUN;
If you plan to use snapshots, then you should also plan a place for them. The following considerations can be taken as a starting point:
If snapshots will exist for a short period after creation, for example, only for the time of backup, then we reserve ten percent of the VM disk size for them;
If snapshots will be used with an average or unpredictable intensity, then it makes sense for them to lay about 30% of the VM disk size;
If snapshots for VMs are actively used (which is relevant in scenarios where VMs are used for testing and development), then the amount occupied by them can be several times larger than the nominal size of virtual disks. In this case, it is difficult to give exact recommendations, but doubling the size of each VM can be taken as a starting point. (Hereinafter, a snapshot refers to the corresponding functionality of ESX(i). The fact is that snapshots can be implemented on a storage system independently of ESX(i), and I mean not the functionality of storage systems.)
An example formula looks like this:
Amount of space for a group of VMs = Number of VMs x (Disk size x T +
Disk Size x S + Memory Size - Memory Size x R).
T - coefficient of thin disks. If such disks are not used, it is equal to 1. If they are, then it is difficult to give an abstract estimate, depending on the nature of the application in the VM. Essentially, thin disks take up less storage space than the disk's nominal size. So - this coefficient shows what proportion of the nominal size is occupied by virtual machine disks;
S is the size of snapshots. 10/30/200 percent, depending on the length of continuous use;
R is the percentage of reserved memory. The reserved memory does not fit into the swap file, the swap file is created in a smaller size. Its size is equal to: the amount of VM memory minus the amount of reserved memory.
Estimated input data, for example, see Table. 1.3.
Table 1.3. Data for planning the volume of the disk subsystem
We obtain an estimate of the required volume:
Infrastructure group - 15 x (20 + 20 x 10% + 2 - 2 x 0) = 360 GB;
Application servers - 20 x (40 + 40 x 10% + 2 - 2 x 0) = 920 GB;
Critical servers - 10 x (100 + 100 x 10% + 6 - 6 x 0.5) = 1130 GB;
Test and temporary - 20 x (20 x 30% + (20 x 30%) x 200% + 2 - 2 x 0) = = 400 GB.
Therefore, we can create two LUNs of 1.4 TB each and distribute virtual machines between them approximately equally. Or create 4-5 LUNs of 600800 GB each and place machines of different groups on different LUNs. Both options (and those in between) are acceptable. The choice between them is made based on other preferences (for example, organizational).
Another resource of the disk subsystem is performance. In the case of virtual machines, MB/s speed is not a reliable criterion, because when a large number of VMs access the same disks, the accesses are inconsistent. For a virtual infrastructure, a more important characteristic is the number of input / output operations (IOPS, Input / Output per second). The disk subsystem of our infrastructure must allow more of these operations than the virtual machines request.
What is the path of guest OS access to physical disks in the general case:
1. The guest OS passes the request to the SAS/SCSI controller driver (which emulates the hypervisor for it).
2. The driver passes it to the SAS/SCSI virtual controller itself.
3. The hypervisor intercepts it, combines it with requests from other VMs and passes the common queue to the physical controller driver (HBA in case of FC and hardware iSCSI or Ethernet controller in case of NFS and software iSCSI).
4. The driver sends the request to the controller.
5. The controller transfers it to the storage system, via a data network.
6. The storage controller accepts the request. This request is a read or write operation from some LUN or NFS volume.
7. A LUN is a "virtual partition" on a RAID array made up of physical disks. That is, the request is passed by the storage controller to the drives in that RAID array.
Where can be the bottleneck of the disk subsystem:
Most likely, at the level of physical disks. The number of physical disks in the RAID array is important. The more of them, the better read-write operations can be parallelized. Also, the faster (in I/O terms) the disks themselves are, the better;
Different levels of RAID arrays have different performance. It is difficult to give complete recommendations, because, in addition to speed, RAID types also differ in cost and reliability. However, the basic considerations are:
RAID-10 is the fastest, but the least efficient use of disk space, deducting 50% for fault tolerance support;
RAID-6 is the most reliable, but suffers from poor write performance (30-40% of RAID-10 at 100% write), although reading from it is as fast as RAID-10;
RAID-5 is a compromise. Write performance is better than RAID-6 (but worse than RAID-10), storage efficiency is higher (the capacity of only one disk is taken for fault tolerance). But RAID-5 suffers from serious problems associated with long data recovery after a disk failure in the case of modern high-capacity disks and large RAID groups, during which it remains unprotected from another failure (turning into RAID-0) and dramatically loses in performance;
RAID-0, or "RAID with Zero Fault Tolerance", cannot be used to store meaningful data;
Storage system settings, in particular the storage controller cache. Studying the documentation of the storage system is important for its proper configuration and operation;
Data network. Especially if you plan to use IP storage, iSCSI or NFS. By no means do I want to say that it is not necessary to use them - such systems have been exploited for a long time and by many. What I'm saying is that you should try to make sure that the load being transferred to the virtual environment will have enough network bandwidth with the planned bandwidth.
The resulting speed of the disk subsystem follows from the speed of the disks and the algorithm for parallelizing disk accesses by the controller (meaning the type of RAID and similar functions). The ratio of the number of read operations to the number of write operations is also important - we take this ratio from statistics or from the documentation for applications in our VMs.
Let's take an example. Let's assume that our VMs will create a load of up to 1000 IOps, 67% of which will be reading, and 33% - writing. How many and what disks will we need in case of using RAID-10 and RAID-5?
In a RAID-10 array, all disks are involved in read operations at once, and only half are involved in write operations (because each block of data is written to two disks at once). In a RAID-5 array, all drives participate in reading, but each block is written with overhead associated with calculating and changing the checksum. You can think of a single write to a RAID-5 array as causing four writes directly to the disks.
Write - 1000 x 0.33% = 330 x 2 (since only half of the disks are involved in the write) = 660 IOps.
In total, we need 1330 IOps from disks. If we divide 1330 by the number of IOps declared in the performance characteristics of one disk, we get the required number of disks in a RAID-10 array for the specified load.
Reading - 1000 x 0.67% = 670 IOps;
Write - 1000 x 0.33% = 330 x 4 = 1320 IOps.
In total, we need 1990 IOps from disks.
According to the manufacturer's documentation, one SAS 15k hard drive handles 150-180 IOps. One SATA 7.2k drive - 70-100 IOps. However, there is an opinion that it is better to focus on slightly different numbers: 50-60 for SATA and 100-120 for SAS.
Let's finish the example.
When using RAID-10 and SATA, we need 22-26 disks.
When using RAID-5 and SAS, we need 16-19 disks.
It is obvious that the calculations I have given are quite approximate. Storage systems use various kinds of mechanisms, primarily caching - to optimize the operation of the storage system. But as a starting point for understanding the disk subsystem sizing process, this information is useful.
Behind the scenes are the methods for obtaining the number of IOPS required for the VM and the read-to-write ratio. For an existing infrastructure (when migrating it to virtual machines), this data can be obtained using special information collection tools, such as VMware Capacity Planner. For the planned infrastructure - from the documentation for applications and your own experience.
The disk and file subsystems of a computer are usually not the subject of special attention of users. The Winchester is a fairly reliable thing and functions as if by itself, without attracting the attention of an ordinary user at all.
By mastering the basic techniques of working with files and folders, such a user brings them to full automatism, without thinking about the existence of additional tools for maintaining a hard disk. Disk management is completely shifted to the operating system.
Difficulties begin either when the file system shows a clear performance degradation, or when it starts to fail. Another reason for a closer study of this topic: installing several "screws" on a PC at the same time.
Like any complex device, a hard drive needs regular maintenance. Windows 7, although it takes care of some of these concerns, it is not able to solve all the problems for you on its own. Otherwise, "brakes" are guaranteed over time. At a minimum, you need to be able to do the following things:
- Clean up the file system from garbage. The concept of garbage includes temporary files, browser cookies that have proliferated, duplicated information, etc.
- Defragment your hard drive. The Windows file system is built in such a way that what the user sees as a whole is actually separate fragments of files scattered over the magnetic surface of the hard drive, united in a chain: each previous fragment knows each next one. To read the file as a whole, you need to put these parts together, for which you need to do a large number of read cycles from different places on the surface. The same thing happens when recording. Defragmentation allows you to collect all these pieces in one place.
- View and correct section information.
- Be able to open access to hidden and system files and folders.
- If necessary, be able to work with several "screws" at once.
And also perform some other useful actions. In our note, we will not discuss the entire range of these issues, but dwell only on a few.
How to read partition information?
For those who are not in the know, let's give an explanation: in Windows there is such a thing as a "snap".
It is an .msc executable that runs like a normal exe. All snap-ins have a uniform interface and are built on COM technology - the basis of the internal structure of this operating system.
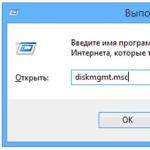
The Disk Management window is also a snap. You can run it by typing in the "Run" window its name diskmgmt.msc as shown in the following figure:
 As a result, we will have a window of the snap-in itself with the heading "Disk Management". Here's what this app looks like:
As a result, we will have a window of the snap-in itself with the heading "Disk Management". Here's what this app looks like:
 This interface is intuitive and simple. In the top panel of the window, we see a list of all volumes (or partitions) on the "screw" with related information about them, such as:
This interface is intuitive and simple. In the top panel of the window, we see a list of all volumes (or partitions) on the "screw" with related information about them, such as:
- Section name.
- Section type.
- Its full capacity.
- Its status (different sections may have different status).
- Remaining free space expressed in gigabytes and percentage of the total.
And other information. The bottom panel contains a list of drives and partitions. It is from here that you can perform operations with volumes and drives. To do this, right-click on the volume name and select a specific operation from the "Actions" submenu.
The main advantage of the interface is that everything is collected here in a bunch - there is no need to wander through different menus and windows to carry out our plans.
Volume Operations
Let's analyze some non-obvious operations with partitions. First, let's discuss the transition from the MBR format to the GPT format. Both of these formats correspond to different bootloader types. MBR is a classic but now obsolete bootloader format.
It has explicit limitations both in volume volume (no more than 2 TB) and in the number of volumes - no more than four are supported. Do not confuse volume and section - these are somewhat different concepts from each other. Read about their differences on the Internet. The GPT format is based on GUID technology and does not have these limitations.
So if you have a large disk, feel free to convert MBR to GPT. True, in this case, all data on the disk will be destroyed - they will need to be copied to another location.
 Virtualization technology has permeated everywhere. It did not bypass the file system either. If you wish, you can create and mount so-called "virtual disks".
Virtualization technology has permeated everywhere. It did not bypass the file system either. If you wish, you can create and mount so-called "virtual disks".
Such a "device" is a regular .vhd file and can be used as a normal physical device - both for reading and writing.
This opens up additional possibilities for cataloging information. This concludes our story. Disk management in Windows 7 is a fairly broad topic, and you can discover a lot of new things by immersing yourself in it.