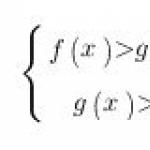고르코프 2015년 2월 24일 오전 11시 41분
데이터 압축 방법
- 알고리즘
나의 상사와 나는 영상처리에 관한 짧은 논문을 준비하고 있다. 저는 이미지 압축 알고리즘에 대한 장을 habra 커뮤니티 법원에 제출하기로 결정했습니다. 한 게시물에 전체 챕터를 담기 어렵기 때문에 세 개의 게시물로 나누기로 결정했습니다.
1. 데이터 압축 방법
2. 무손실 이미지 압축;
3. 손실 이미지 압축.
아래 시리즈의 첫 번째 게시물을 읽을 수 있습니다.
현재 많은 수의 무손실 압축 알고리즘이 있으며 조건부로 두 개의 큰 그룹으로 나눌 수 있습니다.
1. 스트림 및 사전 알고리즘. 이 그룹에는 RLE(run-length encoding), LZ* 계열의 알고리즘이 포함됩니다. 이 그룹의 모든 알고리즘의 특징은 인코딩이 메시지의 기호 빈도에 대한 정보가 아니라 시퀀스에 대한 정보를 사용한다는 것입니다. 이전에 만났습니다.
2. 통계적(엔트로피) 압축을 위한 알고리즘. 이 알고리즘 그룹은 메시지에서 다른 문자가 나타나는 고르지 않은 빈도를 사용하여 정보를 압축합니다. 이 그룹의 알고리즘에는 산술 및 접두사 코딩 알고리즘(Shannon-Fanno, Huffman, 시컨트 트리 사용)이 포함됩니다.
정보 변환 알고리즘은 별도의 그룹으로 분류할 수 있습니다. 이 그룹의 알고리즘은 정보를 직접 압축하지 않지만 해당 응용 프로그램은 스트리밍, 사전 및 엔트로피 알고리즘을 사용하여 추가 압축을 크게 단순화합니다.
스트림 및 사전 알고리즘
실행 길이 코딩
RLE(Run-Length Encoding)는 가장 간단하고 일반적인 데이터 압축 알고리즘 중 하나입니다. 이 알고리즘에서 반복되는 문자 시퀀스는 문자와 반복 횟수로 대체됩니다.예를 들어, 저장하는 데 5바이트가 필요한 문자열 "AAAA"는 2바이트로 구성된 "5A"로 대체될 수 있습니다. 분명히 이 알고리즘은 더 효율적일 수록 반복되는 시리즈가 더 길어집니다.
이 알고리즘의 주요 단점은 반복되지 않는 문자 시퀀스에 대한 효율성이 매우 낮다는 것입니다. 예를 들어 시퀀스 "ABABAB"(6바이트)를 고려하면 RLE 알고리즘을 적용한 후 "1A1B1A1B1A1B"(12바이트)로 바뀝니다. 문자가 반복되지 않는 문제를 해결하기 위한 다양한 방법이 있습니다.
가장 간단한 방법은 다음 수정입니다. 반복 횟수를 인코딩하는 바이트는 반복 횟수뿐 아니라 반복 횟수에 대한 정보도 저장해야 합니다. 첫 번째 비트가 1이면 다음 7비트는 해당 문자의 반복 횟수를 나타내고, 첫 번째 비트가 0이면 다음 7비트는 반복 없이 가져갈 문자 수를 나타냅니다. 이 수정을 사용하여 "ABABAB"를 인코딩하면 "-6ABABAB"(7바이트)를 얻습니다. 분명히 제안된 기술은 반복되지 않는 문자 시퀀스에 대한 RLE 알고리즘의 효율성을 크게 향상시킬 수 있습니다. 제안된 접근 방식의 구현은 목록 1에 나와 있습니다.
- 유형
- 함수 RLEEncode(InMsg: ShortString) : TRLEEncodedString;
- MatchFl: 부울 ;
- MatchCount: shortint ;
- EncodedString: TRLEEncodedString;
- N, i: 바이트;
- 시작하다
- N:=0;
- SetLength(EncodedString, 2 * length(InMsg) ) ;
- 길이(InMsg) >= 1 동안
- 시작하다
- MatchFl : = (길이(InMsg) > 1 ) 및 (InMsg[ 1 ] = InMsg[ 2 ] ) ;
- 매치카운트 := 1 ;
- 동안 (MatchCount<= 126 ) and (MatchCount < length(InMsg) ) and ((InMsg[ MatchCount] = InMsg[ MatchCount + 1 ] ) = MatchFl) do
- MatchCount : = MatchCount + 1 ;
- MatchFl 경우
- 시작하다
- N: = N + 2;
- EncodedString[ N - 2 ] : = MatchCount + 128 ;
- EncodedString[ N - 1 ] : = ord (InMsg[ 1 ] ) ;
- 또 다른
- 시작하다
- 일치하는 경우<>길이(InMsg) 다음
- MatchCount : = MatchCount - 1 ;
- N := N + 1 + MatchCount;
- EncodedString[ N - 1 - MatchCount] : = - MatchCount + 128 ;
- for i := 1 to MatchCount 수행
- EncodedString[ N - 1 - MatchCount + i] : = ord (InMsg[ i] ) ;
- 끝 ;
- 삭제(InMsg, 1, MatchCount) ;
- 끝 ;
- SetLength(인코딩된 문자열, N) ;
- RLEncode := EncodedString;
- 끝 ;
압축된 메시지 디코딩은 매우 간단하며 압축된 메시지를 한 번만 통과하면 됩니다(목록 2 참조).
- 유형
- TRLEEncodedString = 바이트 배열 ;
- 함수 RLEDecode(InMsg: TRLEEncodedString) : ShortString;
- 반복 횟수: shortint ;
- i, j: 단어;
- OutMsg: ShortString;
- 시작하다
- OutMsg := "" ;
- 나는:=0;
- 내가 동안< length(InMsg) do
- 시작하다
- 반복 횟수 : = InMsg[i] - 128 ;
- 나는 : = 나는 + 1 ;
- 반복 횟수인 경우< 0 then
- 시작하다
- 반복 횟수 := abs(반복 횟수) ;
- for j : = i ~ i + RepeatCount - 1 do
- OutMsg := OutMsg + chr (InMsg[ j] ) ;
- 나는 := 나는 + RepeatCount;
- 또 다른
- 시작하다
- j := 1에서 RepeatCount까지 수행
- OutMsg := OutMsg + chr (InMsg[ i] ) ;
- 나는 : = 나는 + 1 ;
- 끝 ;
- 끝 ;
- RLEDecode := OutMsg;
- 끝 ;
RLE 알고리즘의 효율성을 높이는 두 번째 방법은 데이터를 직접 압축하지 않고 압축에 더 편리한 형태로 변환하는 정보변환 알고리즘을 사용하는 것이다. 그러한 알고리즘의 예로서 우리는 Burrows-Wheeler 변환의 발명가의 이름을 따서 명명된 BWT 순열을 고려할 것입니다. 이 순열은 문자 자체를 변경하지 않고 문자열의 순서만 변경하는 반면 순열을 적용한 후 반복되는 하위 문자열은 RLE 알고리즘을 사용하여 훨씬 더 잘 압축된 조밀한 그룹으로 수집됩니다. 직접 BWT 변환은 다음 단계의 순서로 진행됩니다.
1. 다른 곳에서는 발생하지 않는 특별한 줄 끝 문자를 소스 문자열에 추가합니다.
2. 원래 문자열의 모든 순환 순열 가져오기
3. 수신된 문자열을 사전순으로 정렬합니다.
4. 결과 행렬의 마지막 열을 반환합니다.
이 알고리즘의 구현은 목록 3에 나와 있습니다.
- 상수
- EOMsg="|" ;
- 함수 BWTEncode(InMsg: ShortString) : ShortString;
- OutMsg: ShortString;
- LastChar: ANSIChar;
- N, i: 단어;
- 시작하다
- InMsg := InMsg + EOMsg;
- N := 길이(InMsg) ;
- ShiftTable[ 1 ] := InMsg;
- for i := 2 ~ N do
- 시작하다
- LastChar := InMsg[N] ;
- InMsg : = LastChar + copy(InMsg, 1, N - 1 ) ;
- ShiftTable[i] := InMsg;
- 끝 ;
- 정렬(시프트 테이블) ;
- OutMsg := "" ;
- for i := 1 ~ N do
- OutMsg : = OutMsg + ShiftTable[ i] [ N] ;
- BWTEncode := OutMsg;
- 끝 ;
이 변환을 설명하는 가장 쉬운 방법은 특정 예를 사용하는 것입니다. 문자열 "pineapple"을 사용하고 "|" 기호가 문자열의 끝이라는 데 동의합시다. 이 문자열의 모든 순환 순열과 사전순 정렬 결과는 표에 나와 있습니다. 하나.

저것들. 직접 변환의 결과는 "|NNAAAC" 문자열이 됩니다. 이 문자열이 원래 문자열보다 훨씬 낫다는 것을 쉽게 알 수 있습니다. RLE 알고리즘에 의해 압축되었기 때문입니다. 여기에는 반복되는 문자의 긴 하위 시퀀스가 포함됩니다.
다른 변환에서도 유사한 효과를 얻을 수 있지만 BWT 변환의 장점은 가역적이지만 역변환이 직접 변환보다 복잡합니다. 원래 문자열을 복원하려면 다음 단계를 수행해야 합니다.
크기가 n*n인 빈 행렬을 만듭니다. 여기서 n은 인코딩된 메시지의 문자 수입니다.
인코딩된 메시지로 맨 오른쪽 빈 열을 채우십시오.
사전순으로 테이블 행을 정렬합니다.
빈 열이 있는 한 2-3단계를 반복합니다.
줄 끝 문자로 끝나는 문자열을 반환합니다.
역변환의 구현은 언뜻 보기에 어렵지 않으며 구현 중 하나가 목록 4에 나와 있습니다.
- 상수
- EOMsg="|" ;
- 함수 BWTDecode(InMsg: ShortString) : ShortString;
- OutMsg: ShortString;
- ShiftTable: ShortString 배열;
- N, i, j: 단어;
- 시작하다
- OutMsg := "" ;
- N := 길이(InMsg) ;
- SetLength(ShiftTable, N + 1) ;
- for i := 0 ~ N do
- ShiftTable[i] := "" ;
- for i := 1 ~ N do
- 시작하다
- j에 대해 := 1에서 N까지 수행
- ShiftTable[ j] : = InMsg[ j] + ShiftTable[ j] ;
- 정렬(시프트 테이블) ;
- 끝 ;
- for i := 1 ~ N do
- ShiftTable[ i] [N] = EOMsg이면
- OutMsg := ShiftTable[i] ;
- 삭제(OutMsg, N, 1 ) ;
- BWTDecode := OutMsg;
- 끝 ;
그러나 실제로 효율성은 선택한 정렬 알고리즘에 따라 다릅니다. 2차 복잡성이 있는 사소한 알고리즘은 분명히 성능에 극도로 부정적인 영향을 미치므로 효율적인 알고리즘을 사용하는 것이 좋습니다.

일곱 번째 단계에서 얻은 테이블을 정렬한 후 "|" 기호로 끝나는 테이블에서 행을 선택해야 합니다. 이것이 유일한 줄임을 쉽게 알 수 있습니다. 저것. 우리는 특정 예에서 BWT 변환을 고려했습니다.
요약하면 RLE 알고리즘 그룹의 주요 장점은 단순성과 작업 속도(디코딩 속도 포함)이고 주요 단점은 반복되지 않는 문자 집합의 비효율성입니다. 특수 순열을 사용하면 알고리즘의 효율성이 증가하지만 실행 시간(특히 디코딩)도 크게 늘어납니다.
사전 압축(LZ 알고리즘)
RLE 그룹의 알고리즘과 달리 사전 알고리즘 그룹은 문자의 반복 횟수가 아니라 이전에 발생한 문자 시퀀스를 인코딩합니다. 고려 중인 알고리즘이 작동하는 동안 이미 발생한 시퀀스 및 해당 코드 목록이 포함된 테이블이 동적으로 생성됩니다. 이 테이블을 사전이라고 하는 경우가 많으며 해당하는 알고리즘 그룹을 사전이라고 합니다.사전 알고리즘의 가장 간단한 버전은 아래에 설명되어 있습니다.
입력 문자열에서 찾은 모든 문자로 사전을 초기화합니다.
인코딩된 메시지의 시작과 일치하는 가장 긴 시퀀스(S)를 사전에서 찾습니다.
발견된 시퀀스의 코드를 발행하고 인코딩된 메시지의 시작 부분에서 제거합니다.
메시지의 끝에 도달하지 않으면 다음 문자를 읽고 사전에 Sc를 추가하고 2단계로 이동합니다. 그렇지 않으면 종료합니다.
예를 들어, "CUCKOOCOOKOOHOOD" 구에 대해 새로 초기화된 사전이 표에 나와 있습니다. 삼:

압축 프로세스 동안 사전은 메시지에서 발생한 시퀀스로 보완됩니다. 사전 업데이트 프로세스는 표에 나와 있습니다. 4.

알고리즘을 설명할 때 사전이 완전히 채워진 상황에 대한 설명은 의도적으로 생략했습니다. 알고리즘의 변형에 따라 사전의 전체 또는 부분 지우기, 사전 채우기 종료 또는 해당하는 코드 용량 증가로 사전 확장과 같은 다양한 동작이 가능합니다. 이러한 각 접근 방식에는 특정 단점이 있습니다. 예를 들어 사전 보충을 중지하면 사전이 압축된 문자열의 시작 부분에 발생하지만 나중에 발생하지 않는 시퀀스를 저장하는 상황이 발생할 수 있습니다. 동시에 사전을 지우면 빈번한 시퀀스가 제거될 수 있습니다. 사용되는 대부분의 구현은 사전을 채울 때 압축 정도를 추적하기 시작하고 일정 수준 이하로 감소하면 사전을 다시 작성합니다. 다음으로, 사전이 가득 찼을 때 보충을 중지하는 가장 간단한 구현을 고려할 것입니다.
먼저 사전을 발견한 하위 문자열뿐만 아니라 사전에 저장된 하위 문자열의 수를 저장하는 레코드로 정의합니다.
이전에 발생한 하위 시퀀스는 배열 Words에 저장되고 해당 코드는 이 배열의 하위 시퀀스 번호입니다.
또한 사전 검색을 정의하고 사전 기능에 추가합니다.
- 상수
- MAX_DICT_LENGTH = 256 ;
- 함수 FindInDict(D: TDictionary; str: ShortString) : 정수 ;
- r: 정수
- 나: 정수 ;
- fl: 부울 ;
- 시작하다
- r := - 1 ;
- D. WordCount > 0이면
- 시작하다
- 나는 := D.WordCount ;
- fl := 거짓 ;
- 동안 (fl이 아님) 및 (i >= 0) 수행
- 시작하다
- 나는 := 나는 - 1 ;
- fl:=D.단어[i]=str;
- 끝 ;
- 끝 ;
- 만약 그렇다면
- r :=나;
- FindInDict := r;
- 끝 ;
- 절차 AddToDict(var D: TDictionary; str: ShortString) ;
- 시작하다
- 만약 D.WordCount< MAX_DICT_LENGTH then
- 시작하다
- D.WordCount := D.WordCount + 1 ;
- SetLength(D. 단어 , D. 단어 개수 ) ;
- D. 단어 [ D. WordCount - 1 ] : = str;
- 끝 ;
- 끝 ;
이러한 기능을 사용하여 설명된 알고리즘에 따른 인코딩 프로세스를 다음과 같이 구현할 수 있습니다.
- 함수 LZWEncode(InMsg: ShortString) : TEncodedString;
- OutMsg: TEncodedString;
- tmpstr: ShortString;
- D: TDictionary;
- i, N: 바이트;
- 시작하다
- SetLength(OutMsg, 길이(InMsg) ) ;
- N:=0;
- 초기화(D) ;
- 길이(InMsg) > 0 동안
- 시작하다
- tmpstr := InMsg[ 1 ] ;
- 동안 (FindInDict(D, tmpstr) >= 0 ) 및 (length(InMsg) > length(tmpstr) ) 수행
- tmpstr : = tmpstr + InMsg[ 길이(tmpstr) + 1 ] ;
- FindInDict(D, tmpstr)인 경우< 0 then
- 삭제(tmpstr, 길이(tmpstr), 1 ) ;
- OutMsg[N] := FindInDict(D, tmpstr) ;
- N: = N + 1;
- 삭제(InMsg, 1, 길이(tmpstr) ) ;
- 길이(InMsg) > 0이면
- AddToDict(D, tmpstr + InMsg[ 1 ] ) ;
- 끝 ;
- 길이 설정(OutMsg, N) ;
- LZWEncode := OutMsg;
- 끝 ;
인코딩의 결과는 사전에 있는 단어의 수입니다.
복호화 과정은 코드의 직접 복호화로 축소되어 생성된 사전을 전송할 필요가 없으며, 복호화 시에도 부호화 시와 동일하게 사전을 초기화하면 된다. 그런 다음 사전은 이전 하위 시퀀스와 현재 문자를 연결하여 디코딩 프로세스에서 직접 완전히 복원됩니다.
유일한 문제는 다음과 같은 상황에서 가능합니다. 아직 사전에 없는 하위 시퀀스를 디코딩해야 할 때입니다. 현재 단계에서 추가해야 하는 부분 문자열을 추출해야 하는 경우에만 가능함을 쉽게 알 수 있다. 그리고 이것은 부분 문자열이 패턴 cSc를 충족한다는 것을 의미합니다. 즉, 같은 문자로 시작하고 끝납니다. 이 경우 cS는 이전 단계에서 추가한 부분 문자열입니다. 고려된 상황은 아직 추가되지 않은 문자열을 디코딩해야 하는 유일한 경우입니다. 위의 경우 압축된 문자열을 디코딩하기 위해 다음 옵션을 제공할 수 있습니다.
- 함수 LZWDecode(InMsg: TEncodedString) : ShortString;
- D: TDictionary;
- OutMsg, tmpstr: ShortString;
- 나: 바이트;
- 시작하다
- OutMsg := "" ;
- tmpstr := "" ;
- 초기화(D) ;
- for i := 0 to length(InMsg) - 1 do
- 시작하다
- InMsg[i] >= D.WordCount이면
- tmpstr : = D. 단어 [ InMsg[ i - 1 ] ] + D. 단어 [ InMsg[ i - 1 ] ] [ 1 ]
- 또 다른
- tmpstr := D. 단어 [ InMsg[ i] ] ;
- OutMsg := OutMsg + tmpstr;
- 내가 > 0이면
- AddToDict(D, D. 단어 [ InMsg[ i - 1 ] ] + tmpstr[ 1 ] ) ;
- 끝 ;
- LZWDecode := OutMsg;
- 끝 ;
사전 알고리즘의 장점은 RLE에 비해 압축 효율성이 더 높다는 것입니다. 그럼에도 불구하고 이러한 알고리즘의 실제 사용은 일부 구현의 어려움과 관련이 있음을 이해해야 합니다.
엔트로피 코딩
Shannon-Fano Trees로 인코딩
Shannon-Fano 알고리즘은 최초로 개발된 압축 알고리즘 중 하나입니다. 이 알고리즘은 더 자주 사용되는 문자를 더 짧은 코드로 표현한다는 아이디어를 기반으로 합니다. 이 경우 Shannon-Fano 알고리즘을 사용하여 얻은 코드에는 접두사 속성이 있습니다. 어떤 코드도 다른 코드의 시작이 아닙니다. 접두사 속성은 인코딩이 일대일임을 보장합니다. Shannon-Fano 코드를 구성하는 알고리즘은 다음과 같습니다.1. 알파벳을 두 부분으로 나눕니다. 기호의 전체 확률은 가능한 한 서로 가깝습니다.
2. 기호의 첫 번째 부분의 접두사 코드에 0을 추가하고 기호의 두 번째 부분의 접두사 코드에 1을 추가합니다.
3. 각 부분(2개 이상의 문자 포함)에 대해 1-3단계를 재귀적으로 수행합니다.
상대적 단순성에도 불구하고 Shannon-Fano 알고리즘은 단점이 없는 것은 아니며 가장 중요한 것은 최적화되지 않은 코딩입니다. 각 단계의 파티셔닝이 최적이지만 알고리즘이 전체적으로 최적의 결과를 보장하지는 않습니다. 예를 들어 "AAAABVGDEZH" 문자열을 고려하십시오. 해당 Shannon-Fano 트리와 이 트리에서 파생된 코드는 그림 1에 나와 있습니다. 하나:

인코딩이 없으면 메시지는 40비트(각 문자가 4비트로 인코딩된 경우)를 사용하고 Shannon-Fano 알고리즘 4*2+2+4+4+3+3+3=27비트를 사용합니다. 메시지 볼륨은 32.5% 감소했지만 이 결과가 크게 향상될 수 있음을 아래에서 확인할 수 있습니다.
허프만 트리로 인코딩
Shannon-Fano 알고리즘보다 몇 년 후에 개발된 Huffman 코딩 알고리즘도 접두어 속성을 가지고 있으며, 또한 검증된 최소 중복성이 매우 광범위하게 분포하는 이유입니다. 허프만 코드를 얻기 위해 다음 알고리즘이 사용됩니다.1. 알파벳의 모든 기호는 자유 노드로 표시되며 노드의 가중치는 메시지의 기호 빈도에 비례합니다.
2. 자유 노드 집합에서 최소 가중치를 가진 두 개의 노드가 선택되고 선택한 노드의 가중치 합과 동일한 가중치로 새(부모) 노드가 생성됩니다.
3. 선택한 노드가 자유 목록에서 제거되고 이를 기반으로 생성된 상위 노드가 이 목록에 추가됩니다.
4. 여유 목록에 둘 이상의 노드가 있을 때까지 2-3단계를 반복합니다.
5. 구성된 트리를 기반으로 알파벳의 각 문자에 접두어 코드가 할당됩니다.
6. 메시지는 수신된 코드로 인코딩됩니다.
Shannon-Fano 알고리즘의 경우와 동일한 예를 고려하십시오. "AAAABVGDEZH" 메시지에 대해 수신된 허프만 트리 및 코드는 그림 1에 나와 있습니다. 2:

인코딩된 메시지의 크기는 Shannon-Fano 알고리즘보다 작은 26비트로 계산하기 쉽습니다. 이와 별도로, 허프만 알고리즘의 인기로 인해 현재 기호 주파수의 전송이 필요하지 않은 적응 코딩을 포함하여 허프만 코딩에 대한 많은 옵션이 있다는 점에 유의해야 합니다.
허프만 알고리즘의 단점 중 중요한 부분은 구현의 복잡성과 관련된 문제입니다. 주파수를 저장하기 위해 실수 변수 기호를 사용하면 정확도가 떨어지므로 실제로 정수 변수가 자주 사용되지만, 부모 노드의 무게는 지속적으로 증가하고 조만간 오버플로가 발생합니다. 따라서 알고리즘의 단순성에도 불구하고 올바른 구현은 특히 큰 알파벳의 경우 여전히 약간의 어려움을 유발할 수 있습니다.
시컨트 트리로 인코딩
시컨트 함수를 사용한 코딩은 접두사 코드를 얻을 수 있도록 작성자가 개발한 알고리즘입니다. 알고리즘은 트리를 구축한다는 아이디어를 기반으로 하며, 각 노드에는 시컨트 기능이 포함되어 있습니다. 알고리즘을 더 자세히 설명하려면 몇 가지 정의를 도입할 필요가 있습니다.워드는 m 비트의 순서화된 시퀀스입니다(숫자 m을 워드 길이라고 함).
시컨트 리터럴은 비트 값 쌍입니다. 예를 들어, 리터럴 (4,1)은 단어의 4비트가 1과 같아야 함을 의미합니다. 리터럴의 조건이 true이면 리터럴은 true로 간주되고 그렇지 않으면 false입니다.
k 비트 시컨트는 k 리터럴의 집합입니다. 모든 리터럴이 true이면 secant 함수 자체는 true이고 그렇지 않으면 false입니다.
트리는 각 노드가 알파벳을 가능한 한 가장 가까운 부분으로 나눕니다. 그림에. 3은 시컨트 트리의 예를 보여줍니다.

일반적인 경우의 시컨트 함수 트리는 최적의 코딩을 보장하지 못하지만 노드에서의 연산의 단순성으로 인해 매우 빠른 연산 속도를 제공합니다.
산술 코딩
산술 코딩은 정보를 압축하는 가장 효율적인 방법 중 하나입니다. Huffman 알고리즘과 달리 산술 인코딩을 사용하면 기호당 1비트 미만의 엔트로피로 메시지를 인코딩할 수 있습니다. 왜냐하면 대부분의 산술 코딩 알고리즘은 특허로 보호되며 주요 아이디어만 아래에서 설명합니다.사용된 알파벳에 각각 빈도 p_1,…,p_N을 갖는 N개의 문자 a_1,…,a_N이 있다고 가정해 보겠습니다. 그러면 산술 코딩 알고리즘은 다음과 같이 보일 것입니다.
작업 반 간격으로 )